Leposlovje in publicistika
Uvod
Naložimo korpus leposlovnih in publicističnih besedil. Učence vprašamo, kaj določa posamezno skupino besedil. Katera besedila so daljša, katere besede in vrste besed uporablja kateri tip besedil? Bo računalnik razpoznal enake razlike, kot so jih predlagali oni?
Opazovanje podatkov
Podatke naložimo v Corpus. V okvirčku Used text features mora biti samo Vsebina, vse ostalo pa v Ignored text features. Nato Corpus povežemo z gradnikom Porazdelitve. Tam kot spremenljivko izberemo število besed, podatke pa delimo glede na zvrst. Tako lahko vidimo, na primer, katera besedila so daljša in katera krajša.
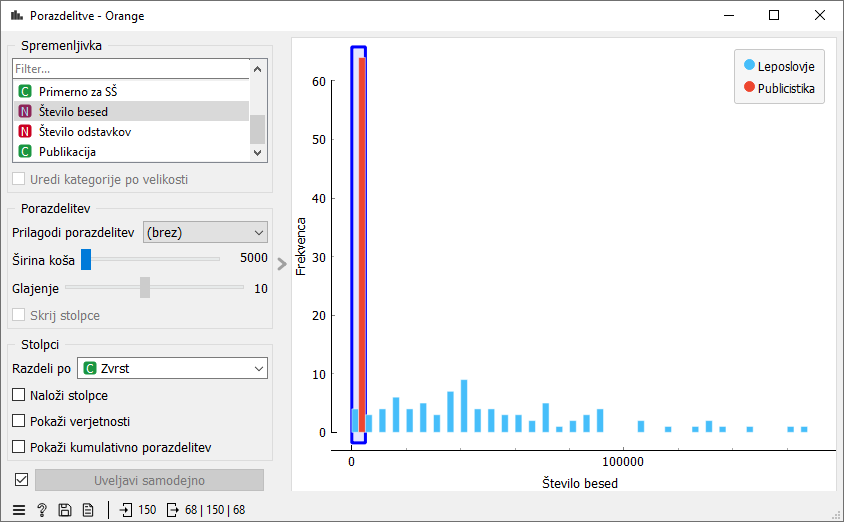
Vprašanje za učence: nekaj leposlovnih besedil je vseeno enako kratkih kot publicistična besedila. Katera leposlovna besedila so to? Vidimo, da sta pravljica in črtica podobnih dolžin kot publicistična besedila.
Priprava podatkov za računalnik
Razložimo, da računalnik ne zna početi ničesar z besedili. Zanj je to kup neuporabnih znakov. Kako besedila beremo ljudje? Kaj je osnovna enota besedil? Tipično ljudje beremo besedila po besedah. To bo tudi naša osnovna enota za analizo.
Najprej moramo torej besedilo razdeliti na osnovne enote, to so besede. Pokažemo primer na tablo. “Očeta sem prosila za knjigo.” → očeta, sem, prosila, za, knjigo.
Super, besede lahko štejemo. Poglejmo najpogostejše besede v korpusu z gradnikom Word Cloud. Opa, kaj je narobe z oblakom besed? Oblak besed namreč vsebuje ločila, ki pa nas ne zanimajo, torej jih je potrebno odstraniti.
Kaj pa storimo z besedami, kot so “je”, “da”, “in”, “se”, “na”? Nam kaj povedo o vsebini besedil? Zakaj (ne)? Te besede so tipično členki, vezniki in predlogi. Če učitelj želi, lahko z učenci ponovi besedne vrste, kot so razvidne iz oblaka besed:
- členki (da, pa, ne)
- vezniki (in, z, ki)
- predlogi (v, na)
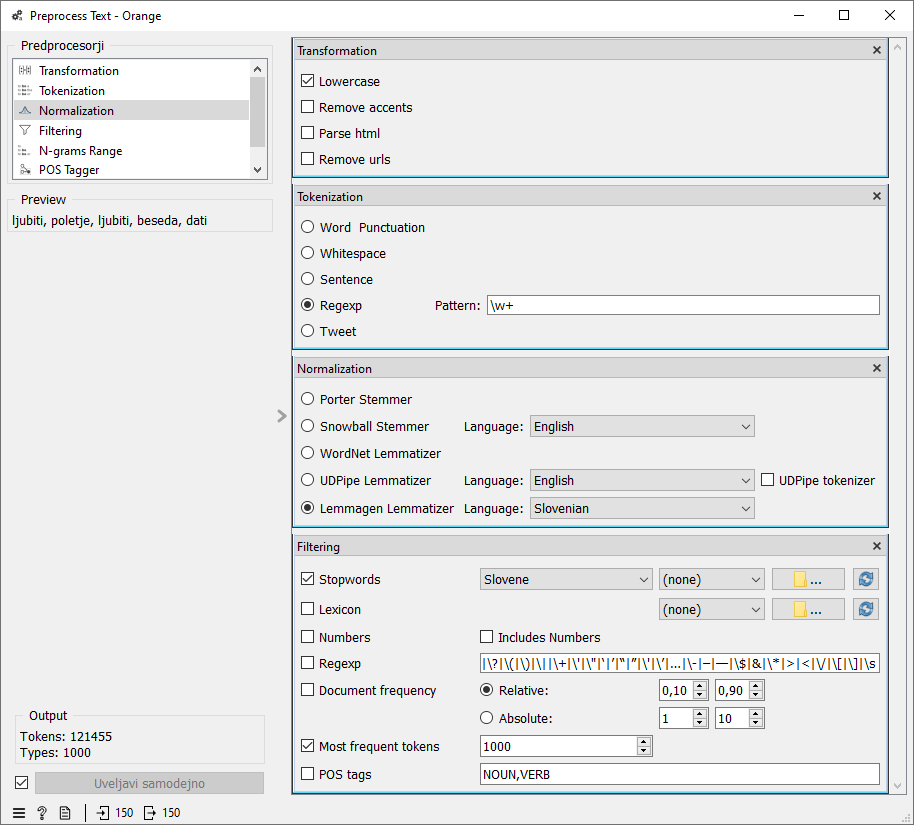
Oblak besed lahko “popravimo”. Računalniku povemo, katerih delov besedila naj ne upošteva. Na primer, lahko odstranimo vsa ločila in nepolnopomenske besede (tem rečemo preprosteje odvečne besede). To storimo z gradnikom Preprocess Text, kjer nastavimo postopek tako, kot smo ga opisali zgoraj. Torej besede pretvorimo v malo začetnico (transformation –> lowercase), razbijemo besedila na besede (tokenization –> regexp) ter odstranimo nepolnopomenske besede (filtering –> stopwords). Pri tem pazimo, da pri izbiri jezika vedno izberemo slovenščino (Slovenian, Slovene). Rezultate vsakega koraka opazujemo v gradniku Word Cloud.
Na enak način pripravimo naš testni stavek. očeta, prosila, knjigo
Ali se je ohranil pomen stavka? Zakaj ja/ne? Kako bi lahko še enostavneje napisali zgornji stavek? oče, prositi, knjiga
Samostalnike v različnih sklonih ter glagole v različnih časih lahko pretvorimo v njihovo osnovno obliko, torej v imenovalnik ednine ter v nedoločnik. Učitelj na tej točki lahko ponovi osnovne oblike besed, na primer tudi za pridevnike. Tako pretvorbo bomo dodali našemu postopku (normalization –> lemmagen), saj ne želimo razlikovati med “prosil”, “prosila” ter “prosili”. Pomensko gre za isto stvar, podajanje prošnje.
Od besedil k številkam
Računalniki so odlični v računanju (kot pove že njihovo ime), v branju besedil pa niso nič kaj dobri. Zato moramo zanje pripraviti besedila v obliki, ki jo računalnik razume. Na primer v obliki številk.
Kako lahko opišemo besedila s številkami? Ena možnost je, da besede preprosto preštejemo. Za vsak dokument oz. besedilo določimo, kolikokrat se posamezna beseda pojavi v njem. Tehnika štetja besed v dokumentih pa se imenuje vreča besed. V gradniku Bag of Words pri možnostih nastavimo Term Frequency na Count, pri ostalih dveh pa (None).
Napovedni model in razlaga
Sedaj smo besedilo mukotrpno pripravili za obdelavo z računalnikom, naš glavni cilj pa je računalnik pripraviti do tega, da bi razlikoval med publicističnimi ter leposlovnimi besedili. Za to bomo uporabili strojno učenje, specifično, naučili bomo napovedni model.
V naslednjem koraku zgradimo napovedni klasifikacijski model, ki bo razlikoval med eno in drugo vrsto besedil. Za to bomo uporabili enega od možnih postopkov za učenje klasifikacijskih modelov, logistično regresijo. Razložimo, da nekatere modele lahko razložimo oz. lahko vidimo, katere spremenljivke so pomembne za njihovo odločanje. Logistična regresija je primer takega modela, ki za posamezno besedo pove, kako pomembna je za razlikovanje med eno in drugo vrsto besedil.
Naš model lahko pogledamo v gradniku, ki se imenuje Nomogram. Ta nam pokaže, katere besede so značilne za leposlovna besedila in katere za publicistična. Višje v nomogramu je beseda, bolj je pomembna za razlikovanje med tipi besedil. Pomembno je tudi, v katero smer je obrnjena x os. Če so višje številke na desni, potem to pomeni, da pogostejša kot je beseda, bolj verjetno bo dokument pripadal izbranemu tipu (v našem primeru leposlovju). In obratno, če številke proti desni padajo, potem redkejša kot je beseda, bolj verjetno bo dokument tega tipa.
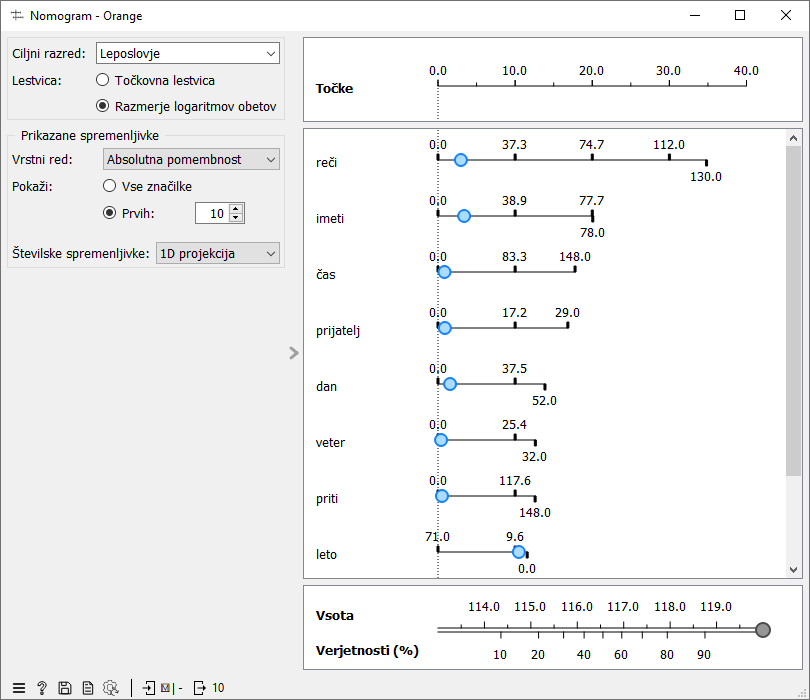
Se učenci strinjajo z rezultati? Zakaj je/ne? Je model dovolj dober, da bi namesto nas pisal test?
Matrika zmot
Če nismo povsem prepričani v rezultate, lahko model preverimo še na en način. Gradnik Bag of Words povežemo z gradnikom Testiraj in meri, nato pa v Testiraj in meri dodamo še povezavo iz Logistične regresije. Testiraj in meri nam oceni, kako dobro deluje model, torej kako uspešno loči med publicističnimi in leposlovnimi besedili. To lahko stori zato, ker smo mu podali tudi informacijo o pravih zvrsteh, ki je zapisana v spremenljivki Zvrst. Tako lahko gradnik Testiraj in meri primerja dejanske tipe dokumentov s tipi, ki jih je napovedal model.
Logistična regresija se občasno tudi zmoti. Njene napake lahko raziščemo v gradniku Matrika zmot. V diagonalnih poljih, obravanih z modro, so pravilno napovedani primeri. Izven diagonale pa so primeri, ki jih je model napačno napovedal. Vidimo, da se je logistična regresija zmotila zgolj pri leposlovnih besedilih. Za 6 leposlovnih besedil je namreč menila, da so publicistična.
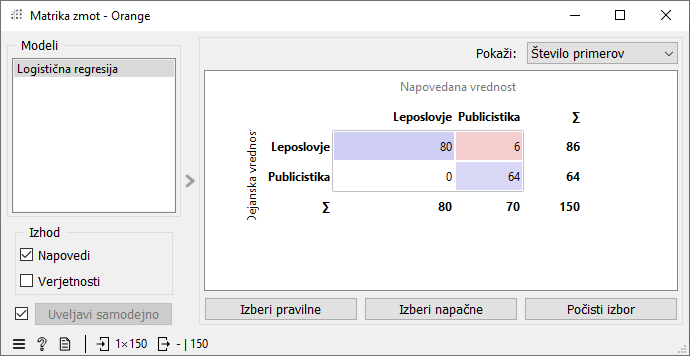
Učenci naj izberejo napačno klasificirana besedila v matriki in jih pregledajo z gradnikom Corpus Viewer. Kaj se jim zdi, zakaj je ta besedila model uvrstil v napačno kategorijo?
Zaključek
Učencem povemo, da računalniki lahko hitro in enostavno pregledamo velike količine besedil. Spomnimo jih na vsiljeno pošto. Njih verjetno ne zanimajo sporočila, ki jih vabijo k nakupu zobne proteze, zato je priročno, če lahko taka neželena sporočila kar avtomatsko odstranimo. Današnji odjemalci elektronske pošte počno prav to - za odstranjevanje neželene pošte uporabljajo modele, ki na podlagi porazdelitve besed znajo razlikovati med željeno in neželjeno pošto.
- Predmet: slovenščina
- Starost: 6. razred
- UI tema: klasifikacija
Materiali za izvedbo
Priprava na uro
- 🖨️ Natisnite to stran
- računalniki z nameščenim programom Orange in dodatkom Text
Umestitev v predmetnik
Z vidika slovenščine: utrjevanje razlikovanja med publicističnimi in leposlovnimi besedili.
Z vidika umetne inteligence: učenci spoznajo, kako delati z zbirkami velikih besedil. Spoznajo, da je besedilo potrebno razdeliti na besede ter nato besede v besedilu prešteti. Nato spoznajo preprost napovedni model – logistično regresijo in izvedo, kako deluje (poenostavljena razlaga). Izvedo, da odločitve modela lahko raziščemo.
Predvideni potrebni gradniki Orangea: Corpus, Porazdelitve, Tabela, Word Cloud, Preprocess Text, Bag of Words, Logistična regresija, Nomogram, Testiraj in meri, Matrika zmot, Corpus Viewer
Učenec:
- prebere daljše sestavke besedil,
- šteje in sešteva večje vsote,
- razloži, kaj določa leposlovna in kaj publicistična besedila,
- nariše, prebere in razloži grafični prikaz (npr. škatlo z brki).