Podobnost narečnih skupin
Uvod
Naložimo korpus slovenskih narečij, v katerem različni govorci opisujejo stare hiše v svojem okolju. Dijake vprašamo, kako določimo narečne skupine, po čem so si podobne oz. različne. Kako bi pripravili značilke, da bi na njihovi podlagi čim bolj uspešno primerjali narečja?
Opazovanje podatkov
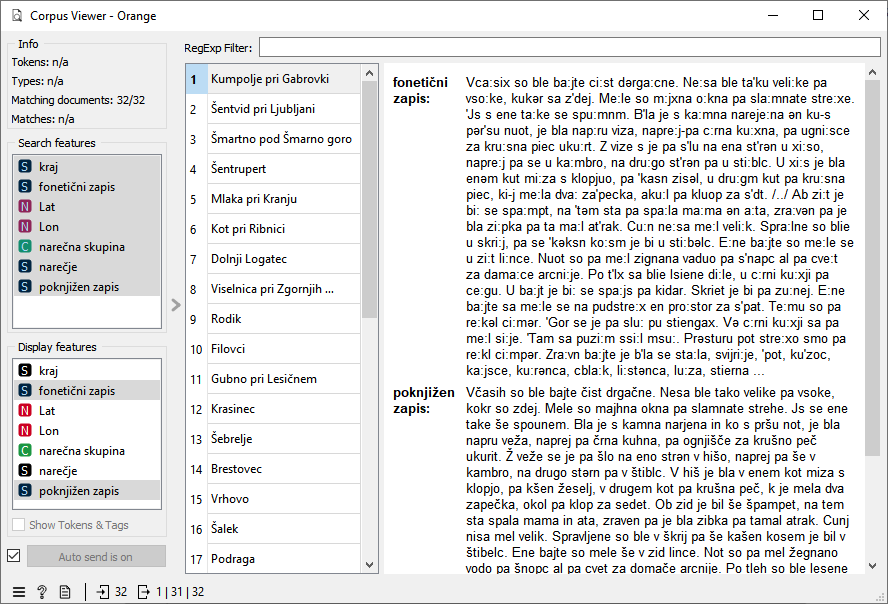
Korpus zajema opise starih hiš v fonetičnem in poknjiženem zapisu. Za to aktivnost bomo uporabili fontetični zapis in opazovali, kateri glasovi so tipični za katero regijo Slovenije.
Podatke naložimo v Corpus in ga povežemo v Corpus Viewer. Tam opazujemo razliko med fonetičnim zapisom in poknjiženim zapisom. Poskušamo ugotoviti, katere značilke so pomembne za razlikovanje.
Priprava podatkov za računalnik
Razložimo, da računalnik potrebuje številski opis dokumentov, da jih bo zmogel primerjati po podobnosti. Kaj bi bila osnovna enota narečij, da bi jih lahko uspešno primerjali? Seveda je to lahko beseda, vendar bi bili za fontetični zapis koristnejši kar posamični znaki oz. zvoki.
Najprej moramo besedilo razdeliti na osnovne enote, torej črke. To storimo z gradnikom Preprocess Text, ki besedilo pripravi za nadaljnjo analizo. Za delitev na črke uporabimo kar regularni izraz \[a-zə\].
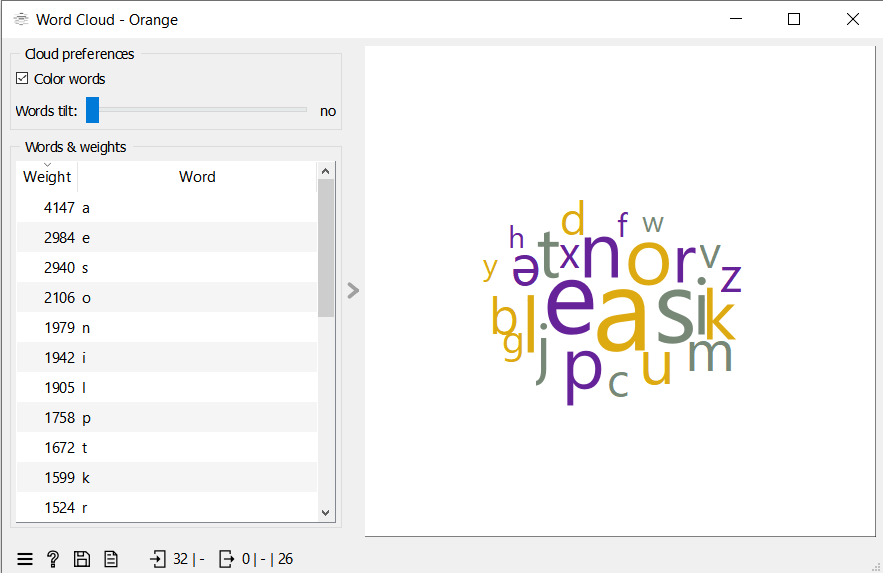
Pogledamo oblak besed in ugotovimo, kateri so najpogostejši zvoki v slovenščini. Očitno a in e, nato s. (Vprašamo jih, če igrajo Wordle ali Besedle. Kako bi jim to znanje pomagalo pri igri?)
Kot smo omenili, računalnik dela s številkami. Besedila smo razbili na posamezne zvoke, nismo pa besedil še številsko opisali. Kako to najlažje storimo? Najverjetneje tako, da preštejemo črke oz. zvoke.
Vzeli bomo naših 26 črk in prešteli, kolikokrat se pojavijo v posameznem besedilu. Temu rečemo vreča besed.
Vendar pa golo štetje ni dovolj. Poglejmo si zapisa iz Šentruperta (kratek) in Vrhovega (dolg). Kaj je narobe s tem, da zgolj štejemo pojavitve? Besedilo iz Vrhovega bo najverjetneje imelo več črk, kot besedilo iz Šentruperta. Nas pa ne zanima, kako dolgo je besedilo, temveč kakšna je pogostost pojavljanja črk.
Da zaobidemo problem visoke pogostosti črk, ki so splošno pogoste v besedilu, lahko uporabimo transformacijo, ki pogostost (rečemo ji tudi frekvenca) uteži glede na to, kako pogosta je črka v besedilu. Če se črka pojavi v vseh besedilih, naj ima nižjo pomembnost (težo), kot črka, ki se velikokrat pojavi v malo besedilih. Ta postopek se imenuje TF-IDF in je zelo priljubljena tehnika v rudarjenju besedil.
Hierarhično razvrščanje
Primerjajmo besedila med sabo. Vzeli bomo preštete črke iz vreče besed in besedila primerjali med sabo. Podobnost bomo izračunali s kosinusno razdaljo, ki ustvari matriko podobnosti oz. razdalj. Matrika razdalj, na primer, lepo pokaže, da je razdalja med primeri zelo podobna razdaljam med kraji, ki jih poznamo iz atlasov.
Nato dodamo Hierarhično gručenje, ki elemente združuje po podobnosti. Najprej se bosta združila elementa, ki sta si najbolj podobna. Nato naslednja dva najbolj podobna elementa, nato naslednja in tako naprej. Lahko združujemo tudi skupine. Če je element najbližje skupini, se ji bo priključil.
Postopek hierarhičnega razvrščanja je možno razložiti s kinestetično aktivnostjo, v kateri oblikujemo skupine učencev glede na dva izmišljena kriterija, na primer znanje matematike in spretnost pri nogometu. Glej pomožno aktivnost Gručenje v razredu.
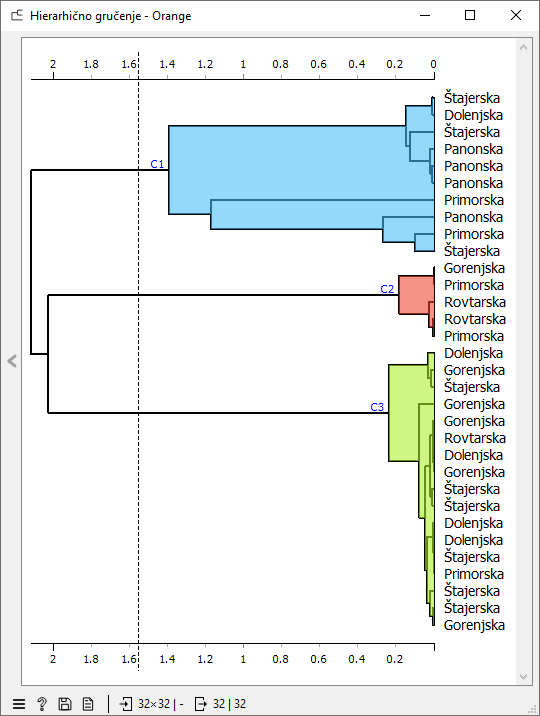
Hierarhično razvrščanje v skupine je prikazano v vizualizaciji, imenovani dendrogram. Dendrogram beremo od desne proti levi, pri čemer pričnemo z besedili v svojih vejah, nato pa jih združujemo po podobnosti. Daljša kot je črta med elementoma, manjša je njuna podobnost.
Dendrogram lahko odrežemo pri poljubni višini tako, da dobimo želeno število skupin. Na primer pet skupin.
Narečne karte
Izbrane skupine lahko pogledamo na zemljevidu, saj vemo, iz katerega kraja prihaja govorec. V podatkih se celo nahajata informaciji o zemljepisni širini in dolžini.
Rezultate hierarhičnega gručenja dodamo v gradnik Zemljevid, kjer točke barvamo po gručah. Vprašamo dijake, ali se jim gručenje zdi smiselno. Zakaj ja/ne?
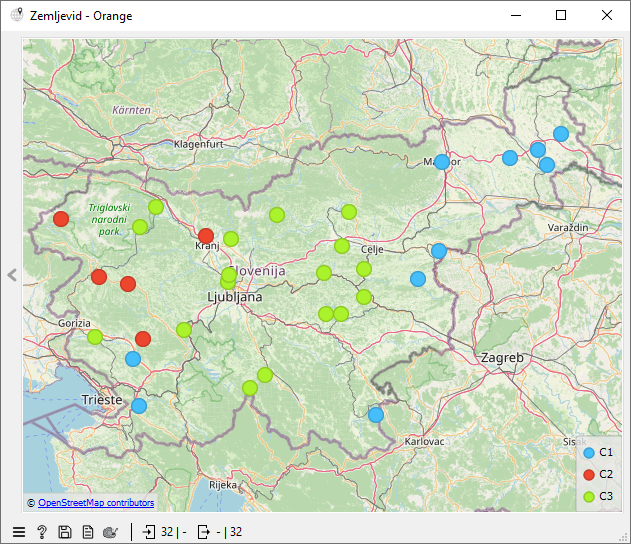
Kaj bi lahko sklepali na podlagi zemljevida?
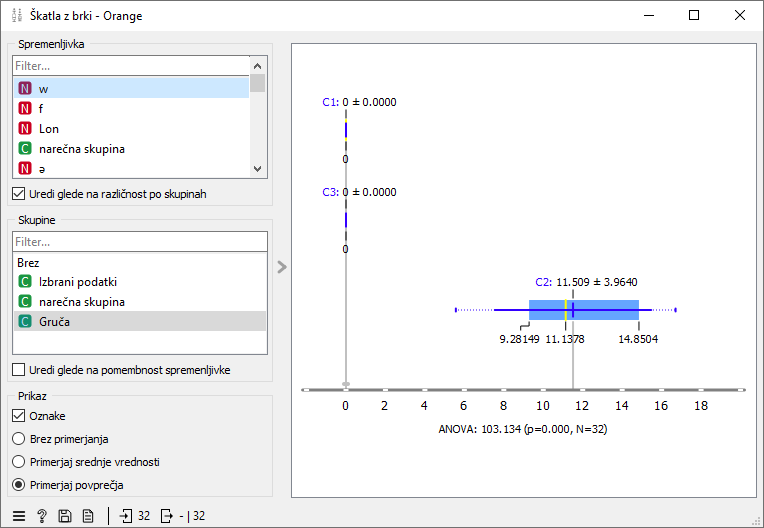
Raziščimo, zakaj se je računalnik tako odločil. Izbrane skupine bomo raziskali v gradniku Škatla z brki. Podatke bomo razdelili po skupinah, kar pomeni, da v razdelku Skupine izberemo spremenljivko Gruča.
Nato uporabimo statistiko, da nam pomaga odkriti tiste spremenljivke, ki najbolje ločujejo skupine. Tej statistiki se reče ANOVA in pomeni oceno razlike med skupinami. V grafičnem prikazu to pomeni, da iščemo take spremenljivke, kjer so skupine čim bolj ločene (imajo čim bolj različne porazdelitve).
To stori možnost “Uredi glede na različnost po skupinah”. Ko jo izberemo, se spremenljivke razvrstijo tako, da bo na vrhu seznama tista spremenljivka, ki najlepše loči med skupinami. Očitno je to črka w, ki predstavlja glas uə. Ta zaznamuje skupino dve, torej primorsko narečje.
Ali veste, kako domačini rečejo Ajdovščini?
Dijaki lahko poskusijo tudi sami. Kaj zaznamuje štajersko narečno skupino? Morda kdo ve, kako na Štajerskem izgovorijo “včasih”?
Zaključek
Dijakom povemo, da računalniki lahko enostavno urejajo velike količine besedil. Lahko jih gručijo (kot smo jih mi), lahko napovedujejo razred (npr. avtorja, pripadnost politični stranki ali sentiment), lahko celo generirajo nova besedila. Gručenje se uporablja zlasti za organizacijo večjih skupin besedil.
- Predmet: slovenščina
- Starost: 1. letnik
- UI tema: gručenje
Materiali za izvedbo
Priprava na uro
- 🖨️ Natisnite to stran
- računalniki z nameščenim programom Orange in dodatkom Text
Umestitev v predmetnik
Z vidika slovenščine: razumevanje podobnosti slovenskih narečij in fonetičnega zapisa.
Z vidika umetne inteligence: dijaki spoznajo, kako delati z zbirkami besedil. Spoznajo, da je besedilo potrebno razdeliti na enote (glasove) ter nato glasove v besedilu prešteti. Nato spoznajo, kako urediti dokumente po podobnosti (glede na fonetično izgovorjavo). Naučijo se raziskati odkrite skupine in jih osmisliti.
Predvideni potrebni gradniki Orangea: Corpus, Preprocess Text, Bag of Words, Razdalje, Hierarhično gručenje, Zemljevid, Škatla z brki
Dijak:
- našteje osnove fonetičnega zapisa,
- našteje narečne skupine in podskupine,
- našteje osnovne parametre delitev na narečne skupine (vsebnost ali odsotnost zvokov, diftongi),
- nariše, prebere in razloži grafični prikaz (npr. škatlo z brki).