Fiction and journalism
The activity is interesting for Slovenian students because it deals with Slovenian texts. However, it can also be modified for other countries (texts in their own language).
Introduction
We upload a corpus of fiction and journalistic texts. Ask students what defines each group of texts. Which texts are longer, which words and types of words are used in which type of text? Will the computer recognise the same differences as they have suggested?
Observing the data
We upload the data to Corpus. Only Content should be in the Used text features frame, everything else in Ignored text features. Then connect Corpus to Distributions widget. There, we select the number of words as a variable and divide the data by type. This allows us to see, for example, which texts are longer and which are shorter.
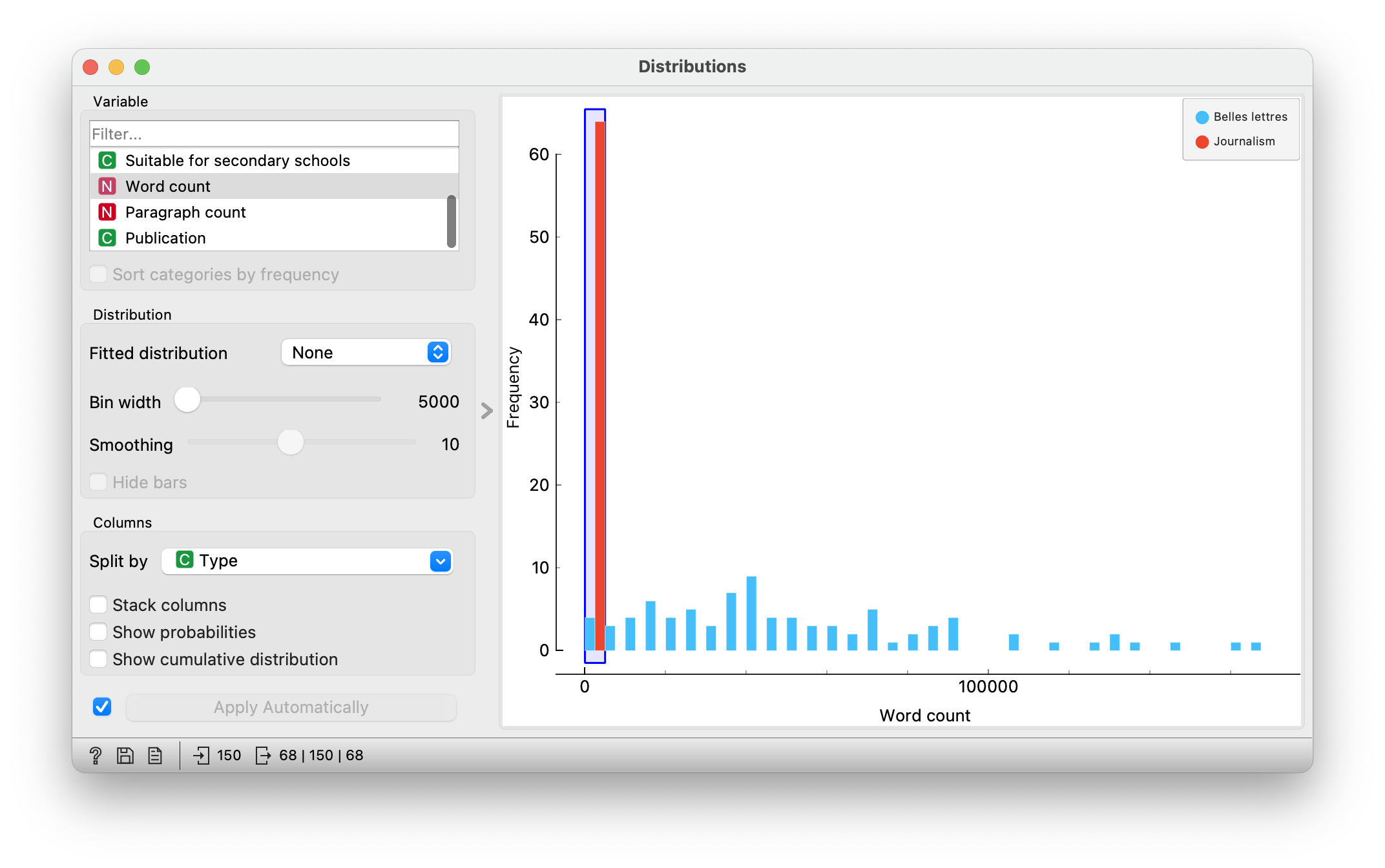
Question for students: some fiction texts are as short as journalistic texts. Which fiction texts are these? We can see that a fairy tale and a comic are similar in length to journalistic texts.
Preparing data for the computer
We explain that the computer can’t do anything with texts. To it, it is a bunch of useless characters. How do humans read text? What is the basic unit of texts? Typically, people read texts word by word. This will be our basic unit of analysis.
So first we need to split the text into basic units, i.e. words. Let’s show an example on the board. “I asked my father for a book.” → I, asked, my, father, for, a, book.
Great, we can count words. Let’s take a look at the most common words from our corpus with the Word Cloud widget. Oops, what’s wrong with the Word Cloud? The word cloud contains punctuation marks that we don’t care about, so we need to remove them.
What do we do with words like “is”, “that”, “and”, “shall”, “on”? Do they tell us anything about the content of the texts? Why (not)? These words are typically particles, conjunctions and prepositions. If the teacher wishes, he/she can review with the students the word types as they are seen in the word cloud:
- particles (yes, well, no)
- conjunctions (and, with, which)
- prepositions (in, on)
We can “fix” the word cloud. We tell the computer which parts of the text to ignore. For example, we can remove all punctuation and unhelpful words (these are simply called stopwords). This is done using the Preprocess Text widget, where we set up the process as described above. So we transform the words to lowercase (transformation –> lowercase), break the text into words (tokenization –> regexp) and remove the non-semantic words (filtering –> stopwords). We make sure that we always choose Slovene when we select the language. If you are working with texts in another language, choose the appropriate language. We observe the results of each step in the Word Cloud widget.
Let’s prepare our test sentence in the same way. → asked, father, book
Has the meaning of the sentence been preserved? Why yes/no? How could the above sentence be written more simply? → father, ask, book
Nouns in different conjugations and verbs in different tenses can be converted to their basic form, i.e. to the nominative singular and to the infinitive. At this point, the teacher can repeat the basic forms of the words, for example for adjectives. We will add such a conversion to our procedure (normalisation –> lemmagen), as we do not want to distinguish between “prosil”, “prosila” and “prosili”. Semantically, they are the same thing, making a request.

From texts to numbers
Computers are great at computing (as their name suggests), but not so good at reading text. That is why we need to prepare texts for them in a form that the computer can understand. For example, in the form of numbers.
How can we describe texts with numbers? One way is simply to count the words. For each document or text, we determine how many times each word appears in it. The technique of counting words in documents is called a bag of words. In the Bag of Words widget, in the options, set Term Frequency to Count, and in the other two options, set (None).
Prediction model and interpretation
We have now painstakingly prepared the text for computer processing, and our main goal is to get the computer to distinguish between journalistic and fiction texts. To do this we will use machine learning, specifically, we will train a prediction model.
In the next step, we build a classification model that will distinguish between one type of text and another. For this, we will use one of the possible procedures for training classification models, logistic regression. We explain that some models can be explained, meaning we can see which variables are important for their decision-making. Logistic regression is an example of such a model, which tells us for each word how important it is to distinguish one type of text from another.
We can look at our model in a widget called Nomogram. It shows which words are typical of fiction texts and which are typical of journalistic texts. The higher up the word is in the nomogram, the more important it is for distinguishing between text types. It is also important which way the x-axis is pointing. If the numbers are higher towards the right, then this means that the more frequent the word, the more likely the document will belong to the selected type (in our case fiction). And vice versa, if the numbers are decreasing towards the right, then the rarer the word, the more likely the document will belong to this type.
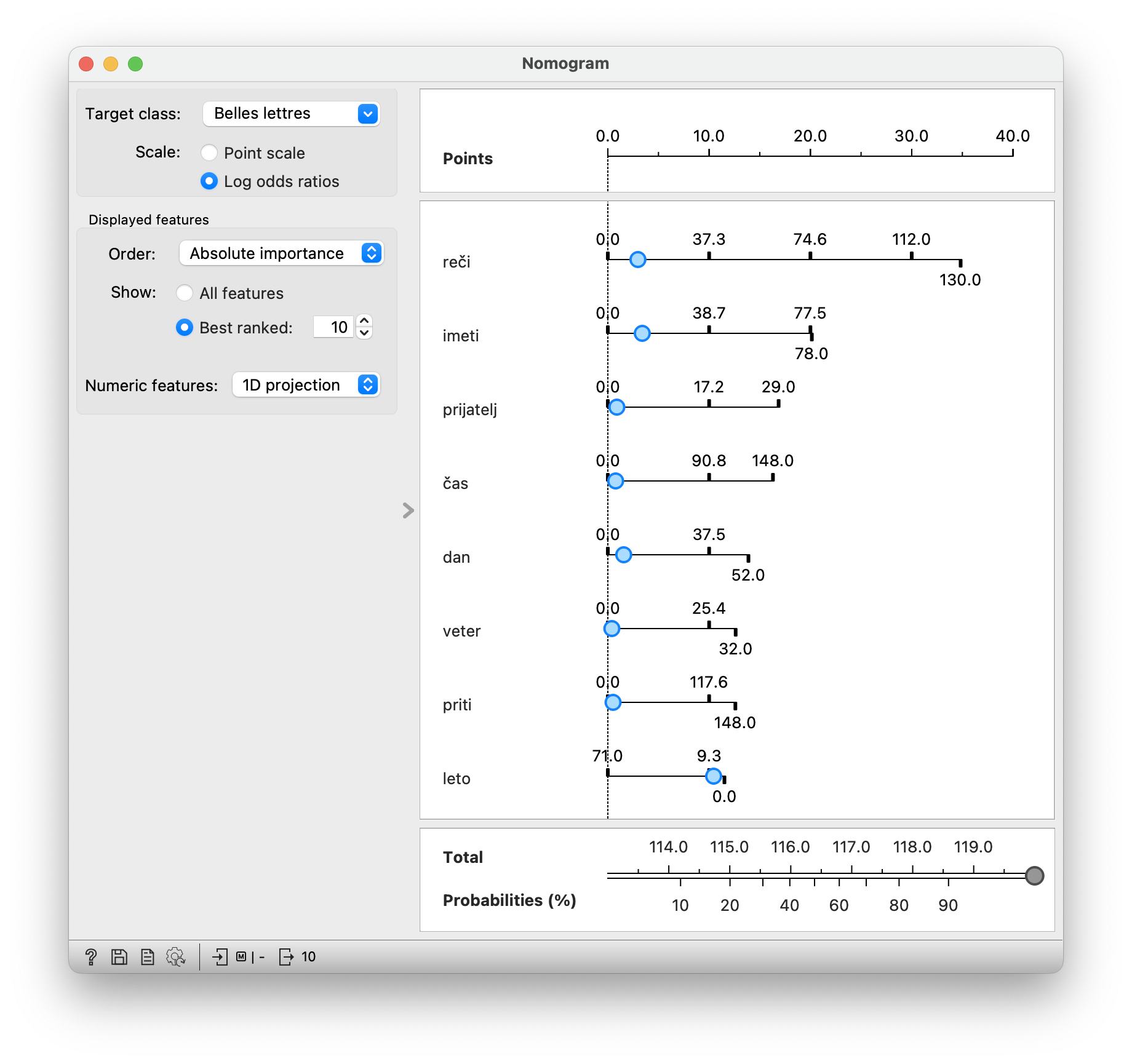
Do students agree with the results? Why yes/no? Is the model good enough to write the test for us?
Confusion Matrix
If you are not sure about the results, there is another way to check the model. We link the Bag of Words to the Test and Score widget, and then add a link from Logistic Regression to Test and Score. Test and Score gives us an estimate of how well the model is working, i.e. how well it distinguishes between journalistic and fiction texts. It can do this because we have also given it information about the right types, which is recorded in the variable Type. This allows the Test and Score widget to compare the actual document types with the types predicted by the model.
Logistic regression is occasionally wrong. Its errors can be explored in the Confusion Matrix widget. The diagonal boxes in blue contain the correctly predicted cases. Off-diagonal are the cases that the model has predicted incorrectly. We can see that the logistic regression was wrong only for fiction texts. In fact, it considered 6 fiction texts to be journalistic.
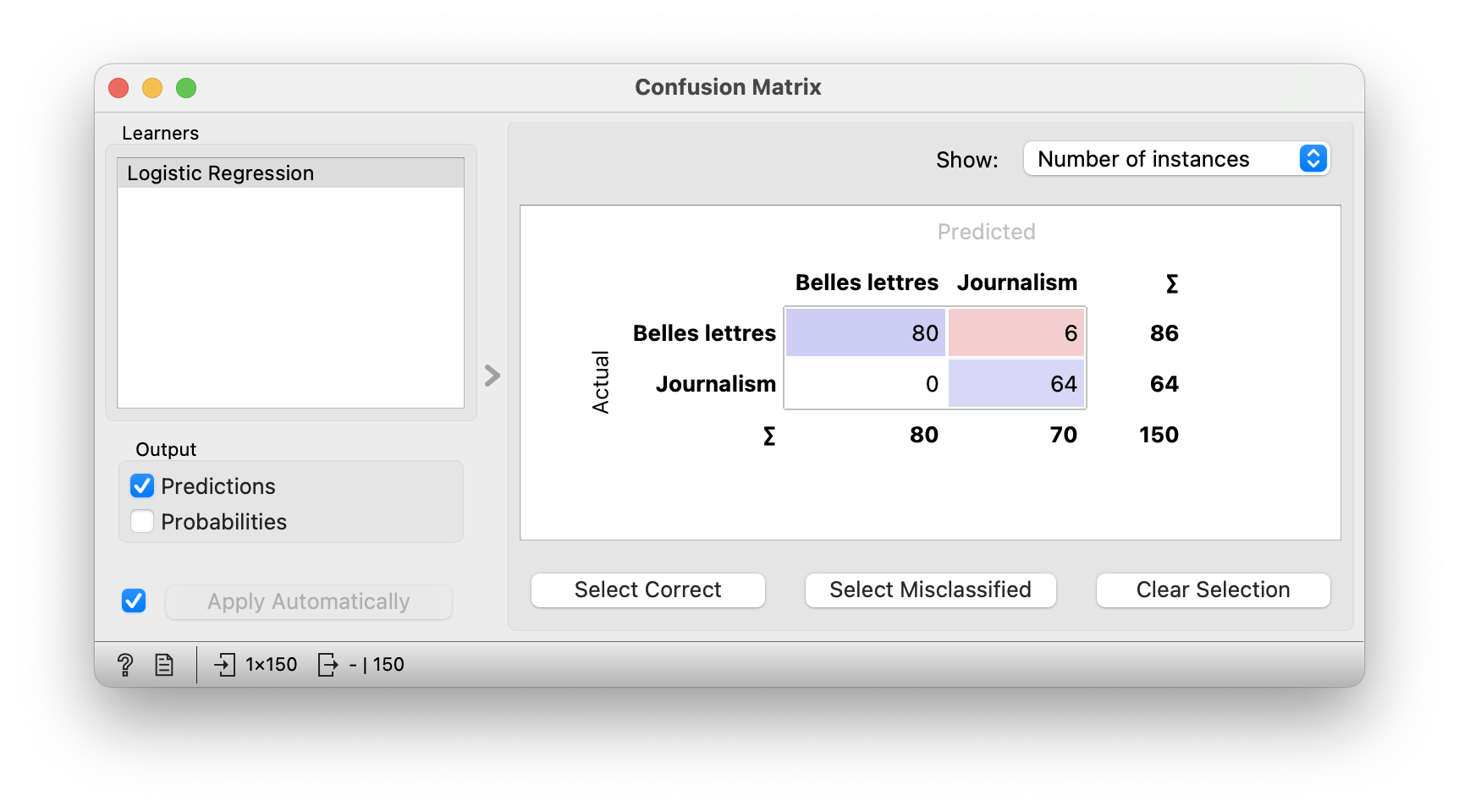
Students should select the misclassified texts in the matrix and examine them with the Corpus Viewer. What do they think is the reason why the model has classified these texts in the wrong category?
Conclusion
We tell students that computers can quickly and easily scan large amounts of text. Remind them about spam. They are unlikely to be interested in messages inviting them to buy dentures, so it is handy if we can automatically remove such spam. Today’s email clients do just that - they use models that can distinguish between spam and non-spam mail based on the distribution of words.
- Subject: slovenian
- Age: 6th grade
- AI topic: classification
- Materials
- Preparation for the lesson
- computers with Orange and Text add-on installed
Placement in the curriculum
In terms of Slovenian: refresh differentiation between journalistic and fiction texts.
In terms of AI: students learn how to work with large collections of texts. They learn how to split a text into words and then count the words in the text. They then learn about a simple prediction model - logistic regression - and how it works (simplified explanation). They learn that the model’s decisions can be investigated.
Foreseen necessary widgets of Orange: Corpus, Distributions, Data Table, Word Cloud, Preprocess Text, Bag of Words, Logistic Regression, Nomogram, Test and Score, Confusion Matrix, Corpus Viewer
Student:
- read longer texts,
- count and add larger sums,
- explain what defines fiction and journalistic texts,
- draw, read and explain a graphic representation (e.g. a box plot).