Slovenian surnames
The activity is interesting for Slovenian students because it deals with Slovenian surnames. However, it can also be adapted for other countries (by searching down the surnames of citizens from other countries and their approximate locations).
The activity can be included in:
- Slovenian, where we focus on the origins of surnames and dialects;
- Geography, where it can be used to revise regions and major places;
- history, as surnames are a good reflection of the connection between different regions throughout history and the result of foreign influences.
The text is therefore not strictly designed as a lesson, but describes possible questions and different points of interest that can be explored, depending on which subject you are doing it in and which class you are doing it in.
About the data
The data refer to the 200 most common Slovenian surnames around the year 2000.
- The file “surnames-slovenia.tab” contains the coordinates of the addresses of 100,000 “persons” with these surnames. The surname frequencies in the data and the geographical distribution correspond to the actual distributions around the year 2000, but these are not real persons living at these coordinates (except by chance). Looking at the data on a map, it is obvious that most of them live in places where there are no actual houses.
- The rows of the file “municipalities-by-surnames.tab” correspond to municipalities and the columns to surnames. For each municipality, it shows how many people with the given surname live in that municipality.
- The file “surnames-by-municipalities.tab” is similar, except that the rows contain the surnames and the columns the municipalities.
Origin of surnames
In the beginning, you can discuss some of the following with your students.
Have people always had surnames? Since when do we have surnames in Slovenia?
The first surnames in Slovenia date back to the 13th century, but they really began to be used in the 15th and 16th centuries. They were given to all of them in 1870, when Emperor Jozef II ordered them to be so.
Why do we even have surnames?
To distinguish between people with the same personal name.
How are English Peterson, Dutch Peterzoon, Slovenian Petrovich, Spanish Perez, Bulgarian Petrov similar?
They all mean “son of Peter”. If there were two Frenchmen living somewhere, they could be distinguished by saying who their father was, one was Peter’s France (or France Petrovich), the other might be Gregor’s France (or France Gregorich). But when surnames became established, someone would be spelled Petrovich, even though his father might have been Jernej and it would be more correct to call him Jernejčič. (There are, of course, other possibilities. If France was of the more sour variety, he might have been called France Jesih, if of the cheerful variety, France Vesel (‘vesel’ means happy in Slovene) or France Prešeren (‘prešeren’ means being in a cheerful mood - and pun intended as France Prešeren was Slovene’s most famous poet).)
In some countries, such as Russia, they not only have a first and last name, but also, officially, the father’s name on all documents. The father of the great writer Lev Nikolayevich Tolstoy must have been Nikolay, and the father of the composer Sergei Vasilyevich Rachmaninoff was undoubtedly Vasily. Some combinations are so common that there are established abbreviations for them. If Alexander names his son Alexander, he will not be called Alexander Alexandrovich, but Sansanich. Joseph’s son Paul will not be called Paul Josephovich, but simply Palosich.
They didn’t just make up the names randomly. Surnames can obviously come from first names. Can we think of any others?
(In Slovene) Klemenčič, Pavlovič, Pavlič, Gregorič, Primožič, Jurkovič… Although such surnames end in -ič, which is typical of surnames from other parts of the former Yugoslavia, they are originally Slovenian surnames. Does anyone in your class have a surname derived from their first name?
Where else can surnames come from? Have you noticed that there are many surnames in Slovenia that come from animal names?
Students can be challenged to list as many of these surnames as possible, for example (in Slovene) Čuk, Medvek, Volk, Vovk, Vouk, Sova, Jarc, Oven, Jazbec, Zajc, Zajec, Jereb, Jelen, Maček, Golob, … They probably called someone Bear (Medved in Slovene) if they were of giant stature, or, perhaps, very overgrown, or had something else bearish about them. The Rabbit (Zajec in Slovene) might have been timid or bouncy, the Wolf (Volk in Slovene), hm, greedy?
Does anyone in the class have a surname like that?
If Jani was a blacksmith (kovač in Slovene), he could be called kovač Jani. Or Jani Kovač. If he was more petite - or, more likely, a blacksmith’s son - he was Jani Kovačič. Do we know of any other surname that comes from a profession?
(In Slovene) Kovač, Kuhar, Žagar, Mlinar, Pečar, Ribič, Kolar, Kmet, Furman, Jager, Žnidar/Žnidaršič/Žnidarič (from a corruption of German Schneider, tailor), Hafner (it could also be Lončar; in England it would be Potter - do you know anyone with that surname?).
(In Slovene) Kralj, Škof, Fuerst and Cesar probably did not reign or bishop, but merely worked for a king, bishop, duke or even emperor. Or maybe they had some other connection to this.
Does anyone in your class have a surname that comes from a profession?
Some surnames tell you where someone came from. If Luka came from Gorjany, it was Luka Gorjanc, if from Dolenjska, it was Luka Dolenc. Do we know any other surnames like that?
(In Slovene) Kranjc, Krajnc and Kranjec; Horvat in many variations; Gorenjc and Dolenc; Lah and Furlan (we can save this one for later in the activity!); Kočevar and Hočevar; Štajerc; Nemec; Ogrin and Vogrin; Purgar and Purger (from the German Bürger, bourgeois - member of the middle class)…
Frequency of surnames
What are the most common Slovenian surnames?
Use the File widget to open the “surnames-slovenia.tab” file. Link the widget to the Box Plot widget. There, select the variable “surname”, the group “surname” and sort by the frequency of the groups.
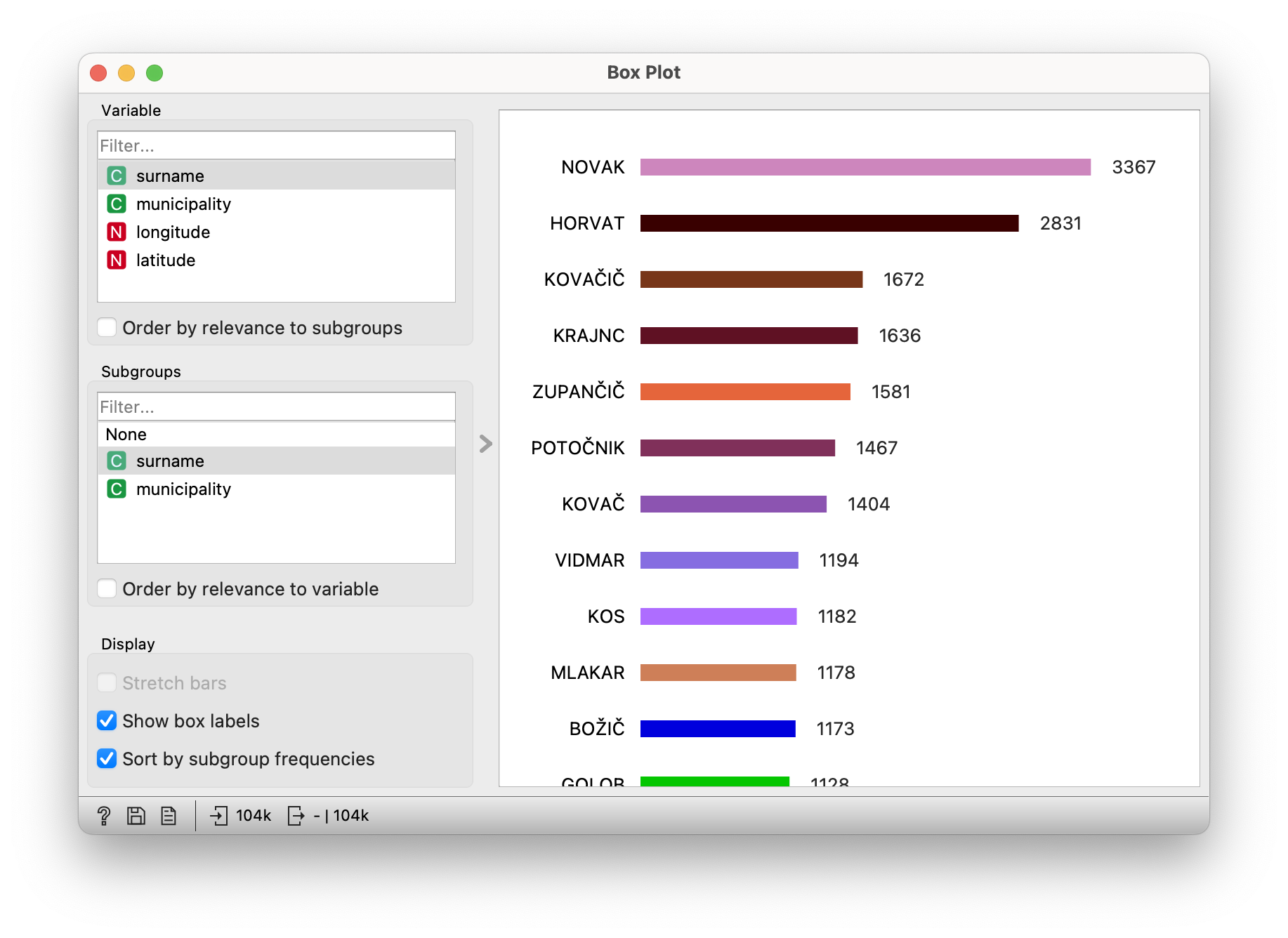
The distribution is interesting: the two most common surnames are somehow twice as common as the third most common, and then the frequency drops rapidly. The first two are therefore NOVAK and HORVAT. We can let the students guess the first one; the second one will only be successfully guessed in … well, we know in which part of Slovenia. We know, don’t we? We don’t? Then just read on. 😃
The data can also be observed using the Distributions widget, but the large amount of data makes it more difficult to see surname names. This is corrected by displaying them in a table. We create a File - Distributions - Data Table workflow. The default link between Distributions and Table is not the one we would like, so double-click on it and link Histogram Data to Data.
In the table we see the list, ordered by frequency.

What surnames are they? Where do they come from?
- A Novak is someone who has been conscripted into the army, or is a new arrival in a village, or someone who has cut down and cleared a forest to make a field.
- Horvat probably came from Croatia, and they called him Horvat.
- Kovačič comes from blacksmith.
- Krajnc apparently came from the Krajna region. (And not from Kranjska, because then he would have been a Kranjc.)
- Zupančič is a diminutive of Zupan and may mean mayor or administrator. Or someone related to him.
- A Potočnik will simply be someone who lives somewhere near a brook.
Surname distribution in Slovenia
Are all surnames equally common throughout Slovenia?
(If it’s a smaller town, you could ask students here about the most common surnames in their town. Typical surnames are most easily found in the cemetery. In smaller towns, a few surnames are usually prevalent in cemeteries. This is a good exercise for school trips. In one place, you go to the cemetery and see that more or less everyone there spells their surname Štajdohar.)
We link the File widget to the Select Rows widget, and then this one to the Geo Map widget.
Now select surnames in Select Rows and see where they appear on the map.
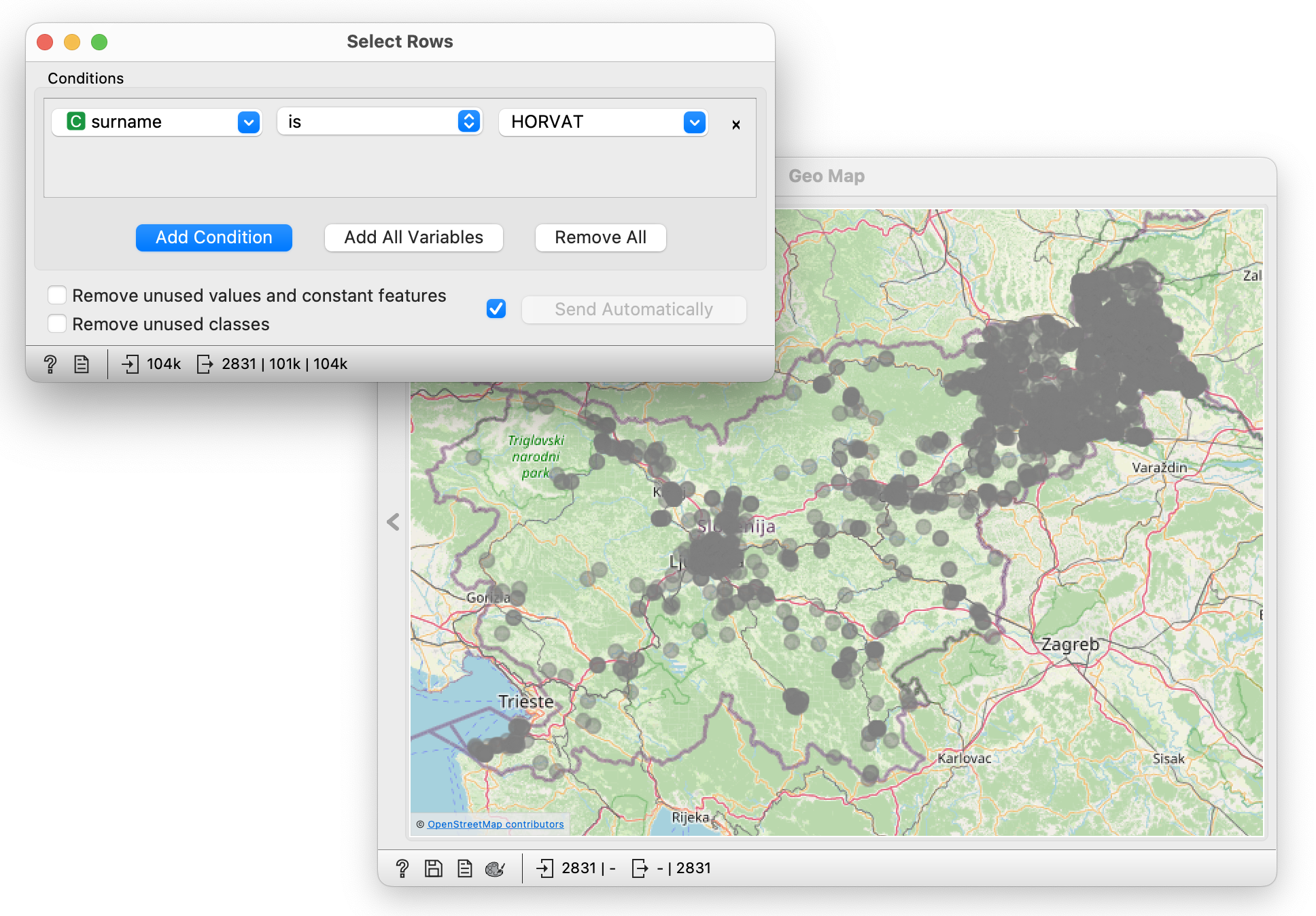
Why would Horvati be exactly here? People who immigrated from Croatia were called Hrovat, Hrobat, Horvatin, Horvatič in various dialects… Horvat is apparently a Pomeranian version of this surname.
At this point you can
- observe the different surnames and think about why they are where they are;
- observe the locations of some other common surnames (Novak is everywhere, Zupanc is in Gorenjska);
- observe the distribution of surnames that are common in the region where your school is located, or the surnames of the students that appear in the data;
- look for any strictly localised surnames, for example Trček, Toplak, Gomboc or Ramšak.
Here are some more interesting questions.
- Why are the Gorenjc people in Dolenjska, and the Dolenc people everywhere except in Dolenjska?
- Why are the Furlan in Goriška and Primorska? What does the Furlan surname mean?
- Where did the Korošc immigrate to?
- Where in Slovenia did they need Kovač (blacksmiths)? There as Novak - everywhere. :)
Dolenc 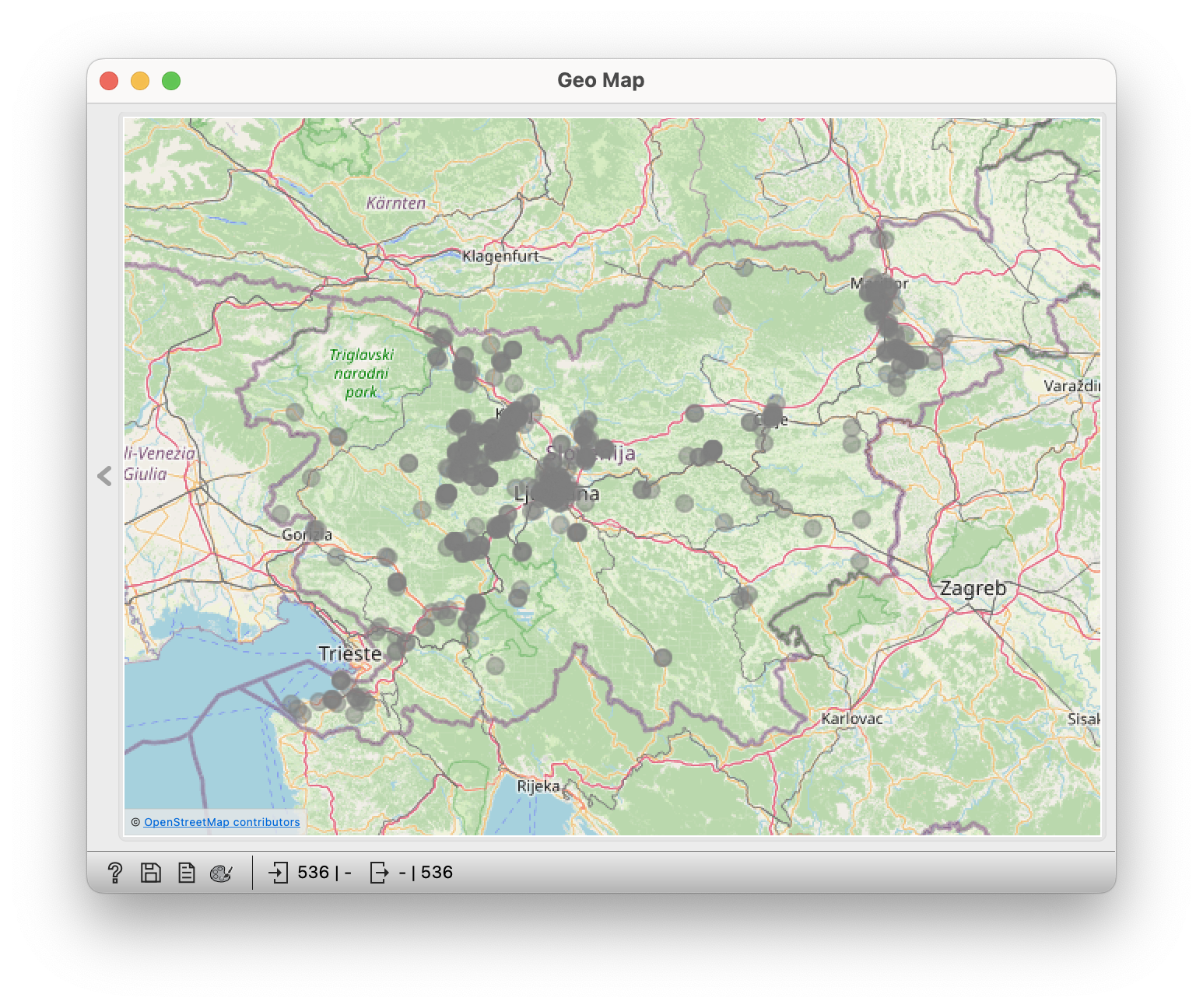 | Gorenc 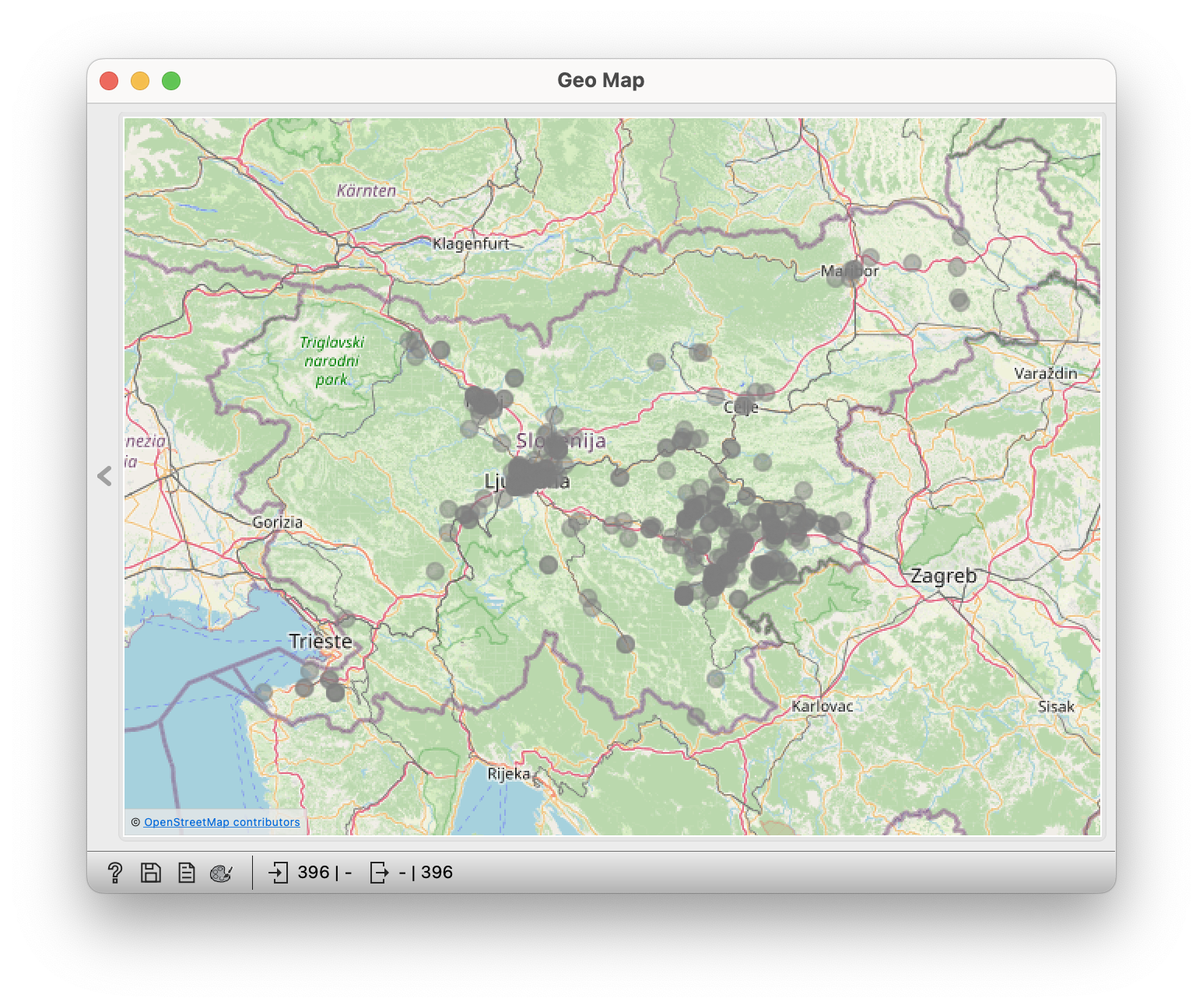 |
Kovač 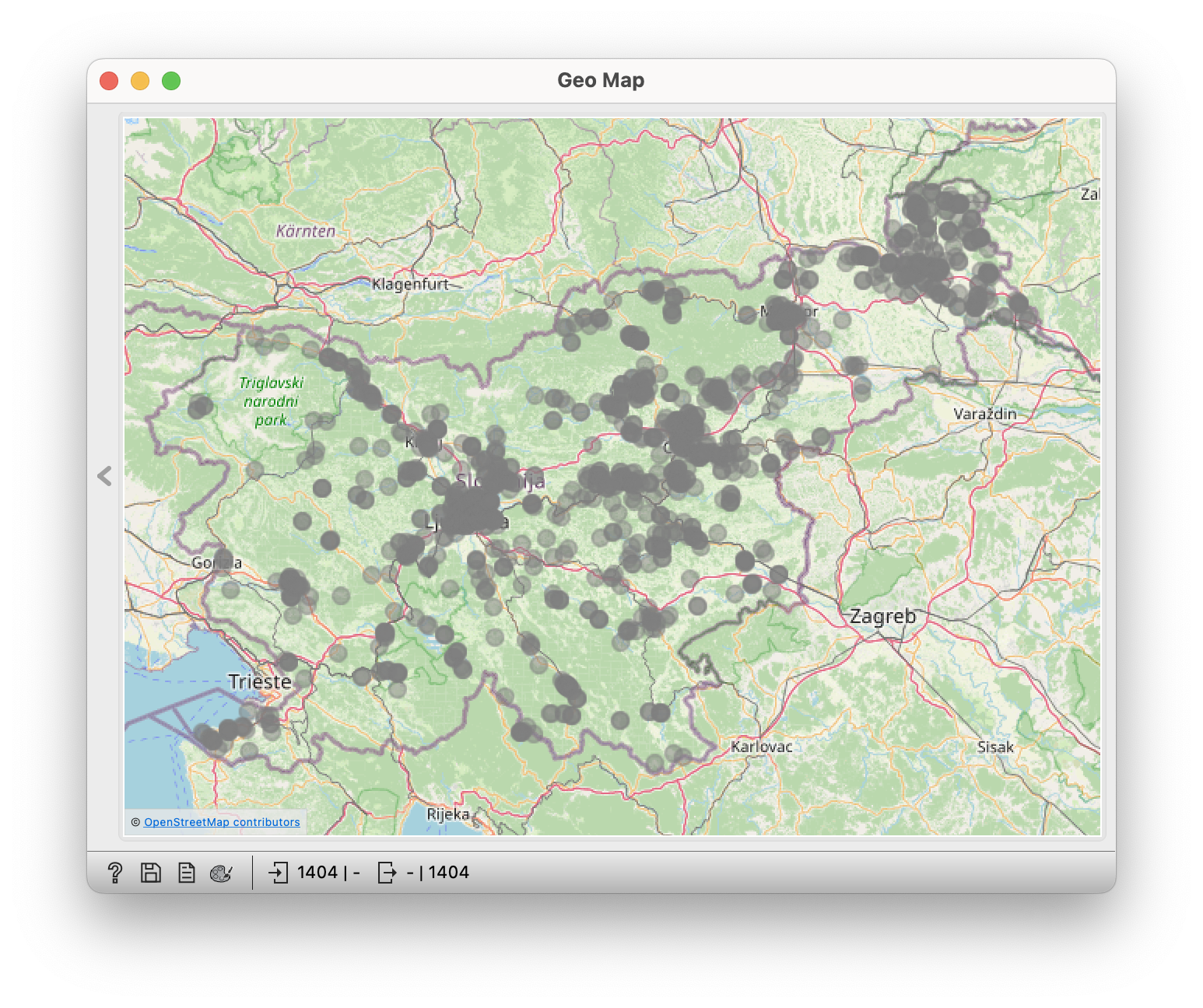 | Korošec 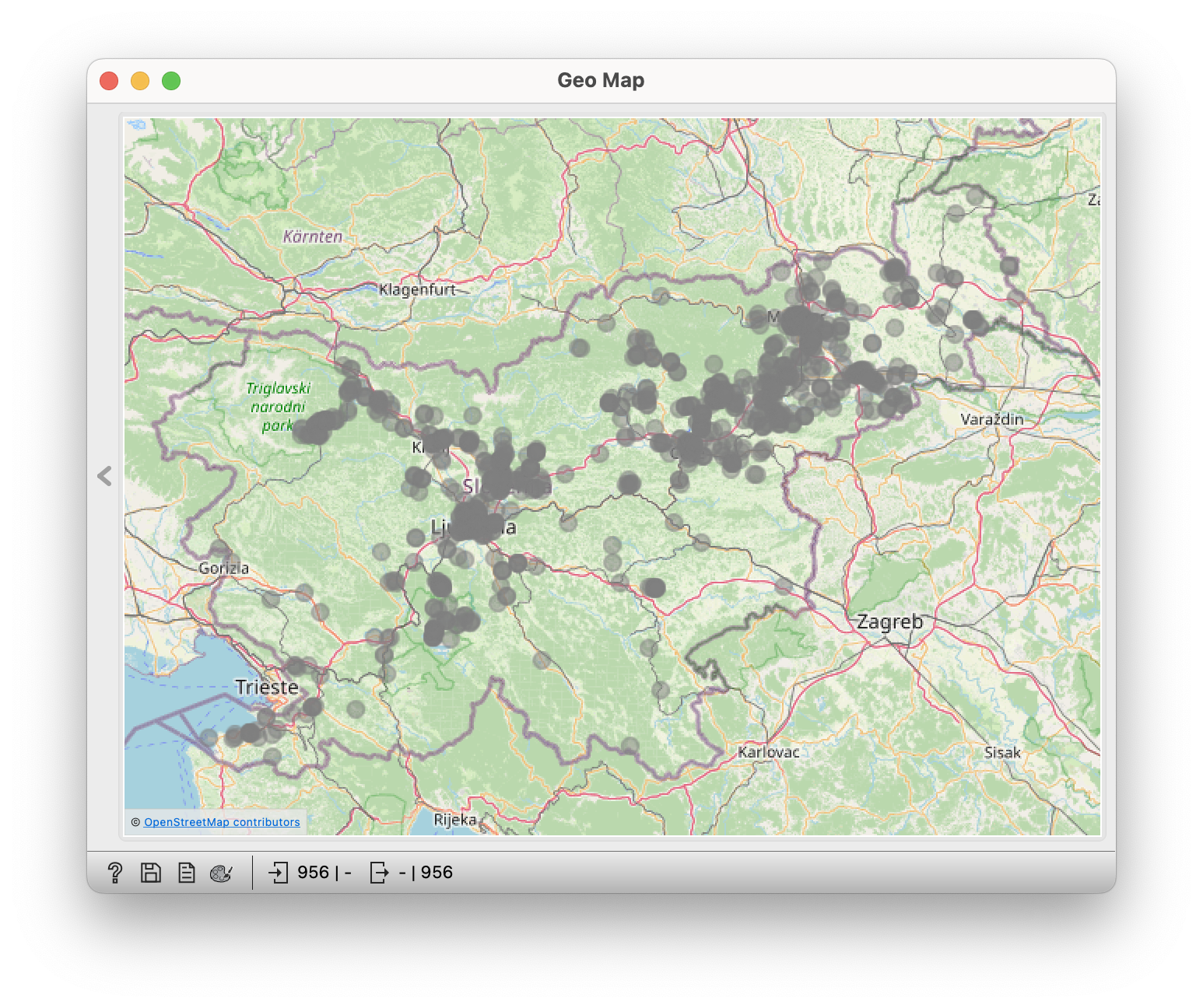 |
Furlan 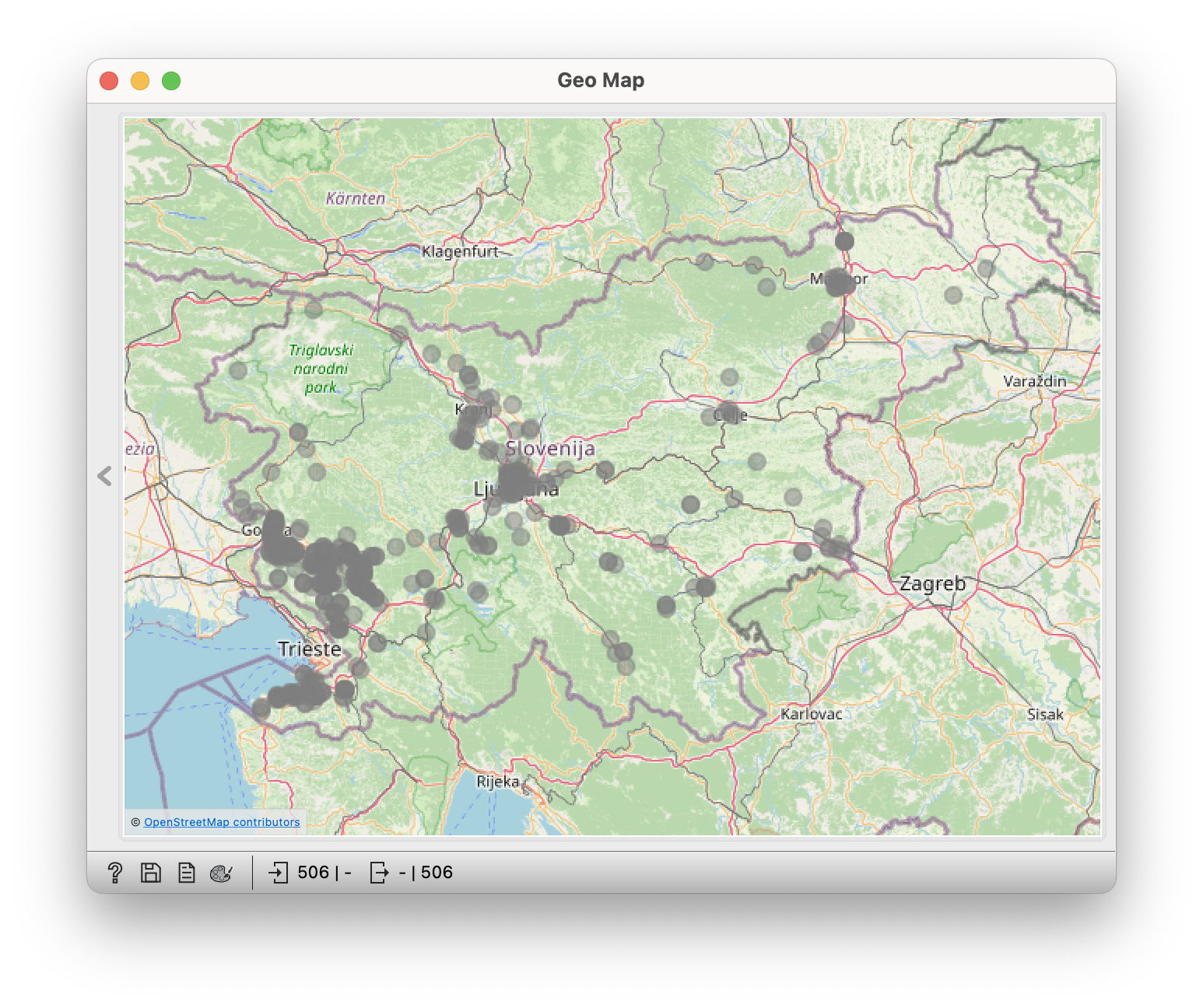 | Trček 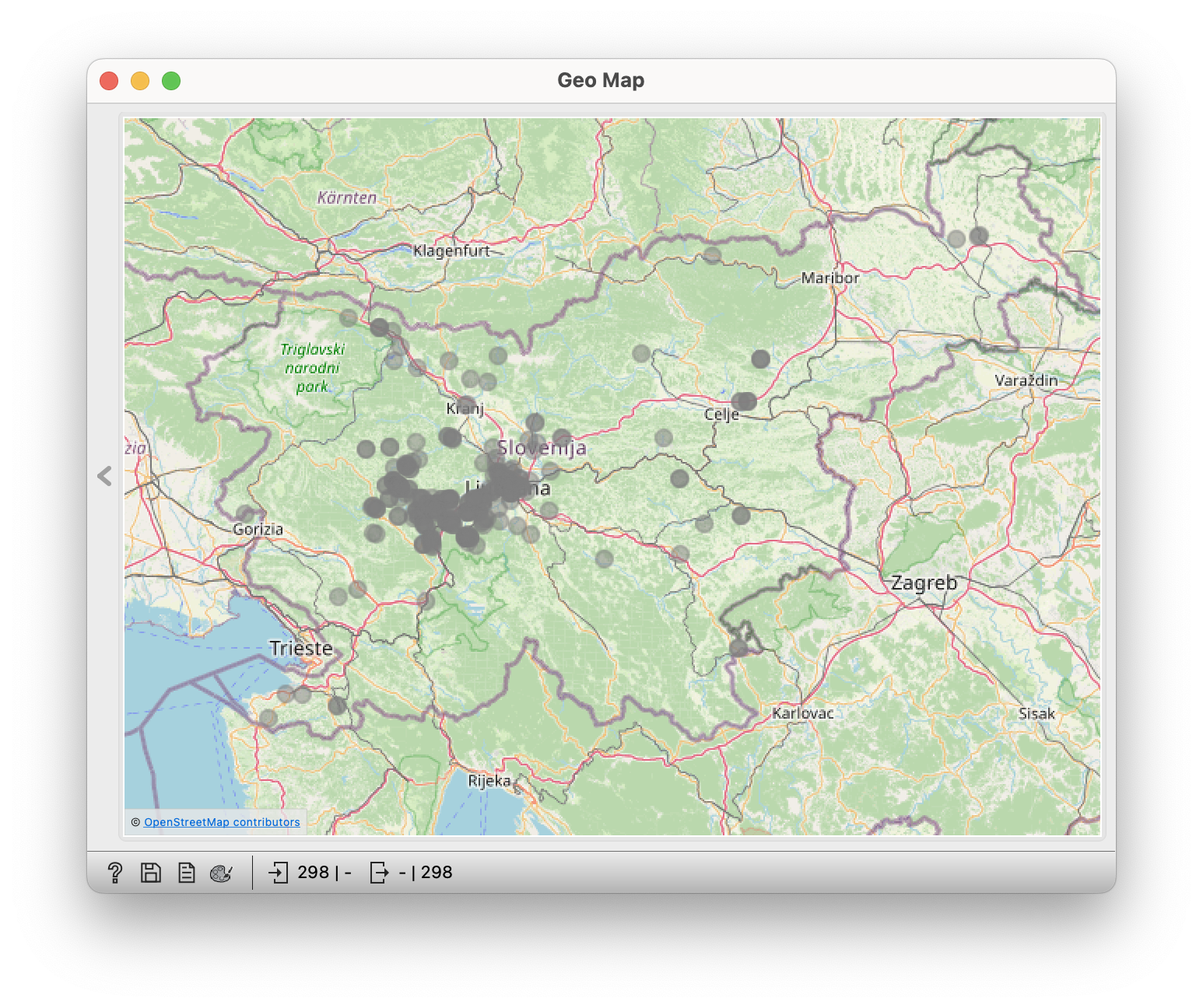 |
Similarities between regions
How can we divide Slovenia into regions based on surnames? And what does this tell us about our history?
We’ll start with information about surnames in a given municipality. Based on this, we will group the municipalities into a number of clusters, and these clusters will represent the “surname regions” of Slovenia.
We will set up such a workflow:

- Load “surnames-by-municipalities.tab” in File
- In Distributions select cosine. This will calculate the difference between all pairs of municipalities: two municipalities are more similar the more similar the frequency of surnames in them. Since the municipalities are of different sizes, we have to look at the frequencies of the surnames “relatively”; this is done by the cosine distance. (We won’t go into a more detailed explanation here.)
- In Hierarchical Clustering, under Linkage, we select Ward. (Again, we will not elaborate on this.)

On the right side of the Hierarchical Clustering widget we now see the hierarchy of groups. Šmartno pri Litiji is obviously at Litija, while Dol pri Ljubljani is just around the hill, so it is not surprising that they have similar surnames there too. Beyond the smaller ridge of hills is Domžale, from where the neighbouring valleys lead to Moravče and Lukovica. These three municipalities have similar surnames, so they form a group of their own, but at the same time they are similar to the group of Litija, Šmartno pri Litiji and Dol pri Ljubljani, since people apparently moved back and forth between these valleys, so surnames were mixed.
Some smaller municipalities also find themselves in strange places: easternmost Bovec is next to southernmost Kostel. Which of them does not belong where it is placed? (Bovec. From Kostel, we casually ascend to the Loški potok and from there descend to Ribnica.)
Ljubljana, Jesenice, Piran, Kočevje are also in strange places. We can only guess why: perhaps these are places where people have migrated from all over Slovenia: to Ljubljana because it is the capital, to Jesenice perhaps because of industry and the number of workers in the ironworks has exceeded the number of locals, Piran is by the sea and so perhaps people are moving there, and Kočevje was practically emptied after the Second World War, so people from elsewhere have been moving to these places en masse. Places with a certain general mix of surnames may have similarities.
In the classroom, you can search for your municipality and see where it belongs.
Obviously, this is also a nice opportunity to revise the geography of Slovenia in Year 9 (according to the Slovenian curriculum).
Hierarchical clustering does not determine the number of groups, but rather builds a hierarchy. You determine the number of groups by “cutting” the hierarchy at a certain point, or by telling the computer how many groups you would like, and the computer will determine the cut itself. Here we will use the latter. Select “Top N” and press the up and down keys next to the number to determine the number of groups.
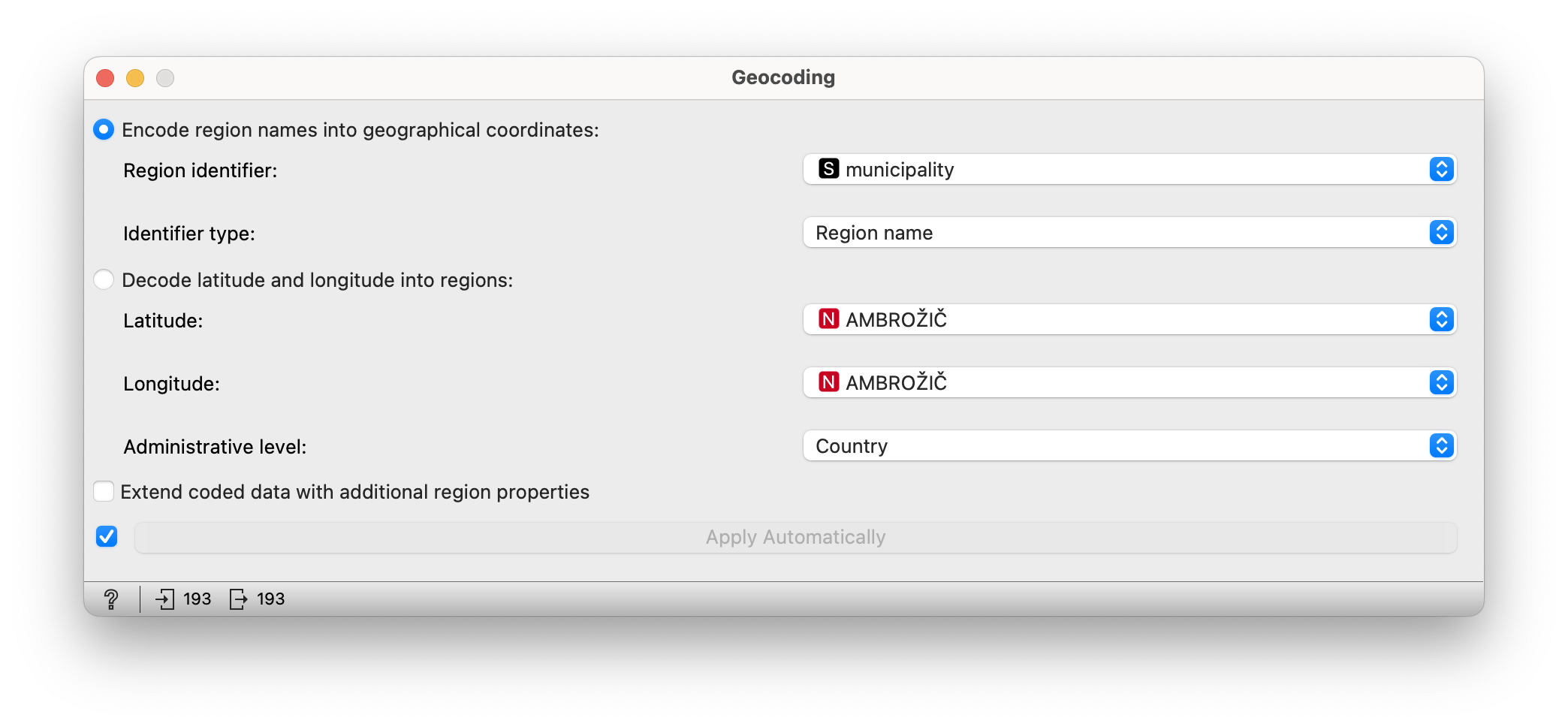
Let’s start by asking for two groups. Let’s link the Hierarchical Clustering widget to the Geocoding widget (see image above), which will assign coordinates to each municipality on the map. (The only important settings are at the top of the Geocoding widget, where we tell it to observe the “municipality” column, which should be “Region name”.)
We continue with the Choropleth Map widget, which colours each municipality according to the group it belongs to. We set the Choropleth Map as shown in the figure: we need to increase the level of detail so that it colours the municipalities and not the broader areas.
So, if we were to split Slovenia into two regions, the division would be as follows:

Obviously, Pomurje has been a “region unto itself” in Slovenian history. (Prekmurje, for example, is the most difficult Slovenian dialect for many people to understand, as it has a Hungarian influence.)
Let’s ignore special features such as the Loški potok. Perhaps the municipality is too sparsely populated and we have too few surnames of people from it, or its surnames are too unique and do not appear among the most common 200. Probably mostly the former.
If we increase the number of groups in the Hierarchical Clustering to 3, Koroška and with it the eastern part of Štajerska emerge. This means that the Dolenjska, Gorenjska, Notranjska and Primorska surnames are relatively similar to each other compared to the Štajerska surnames (let alone the Pomurska surnames). There is therefore a historical internal border; there has been less migration across here than in the rest of Slovenia.
When we claim four groups, we are not yet dividing the large, central group, but separating the Prekmurans from the Prleks! (Where is the border? Mura. The Prekmurks are across the Mura, the Prleks are not, but are somehow between the Drava and the Mura.)
Three clusters  | Four clusters 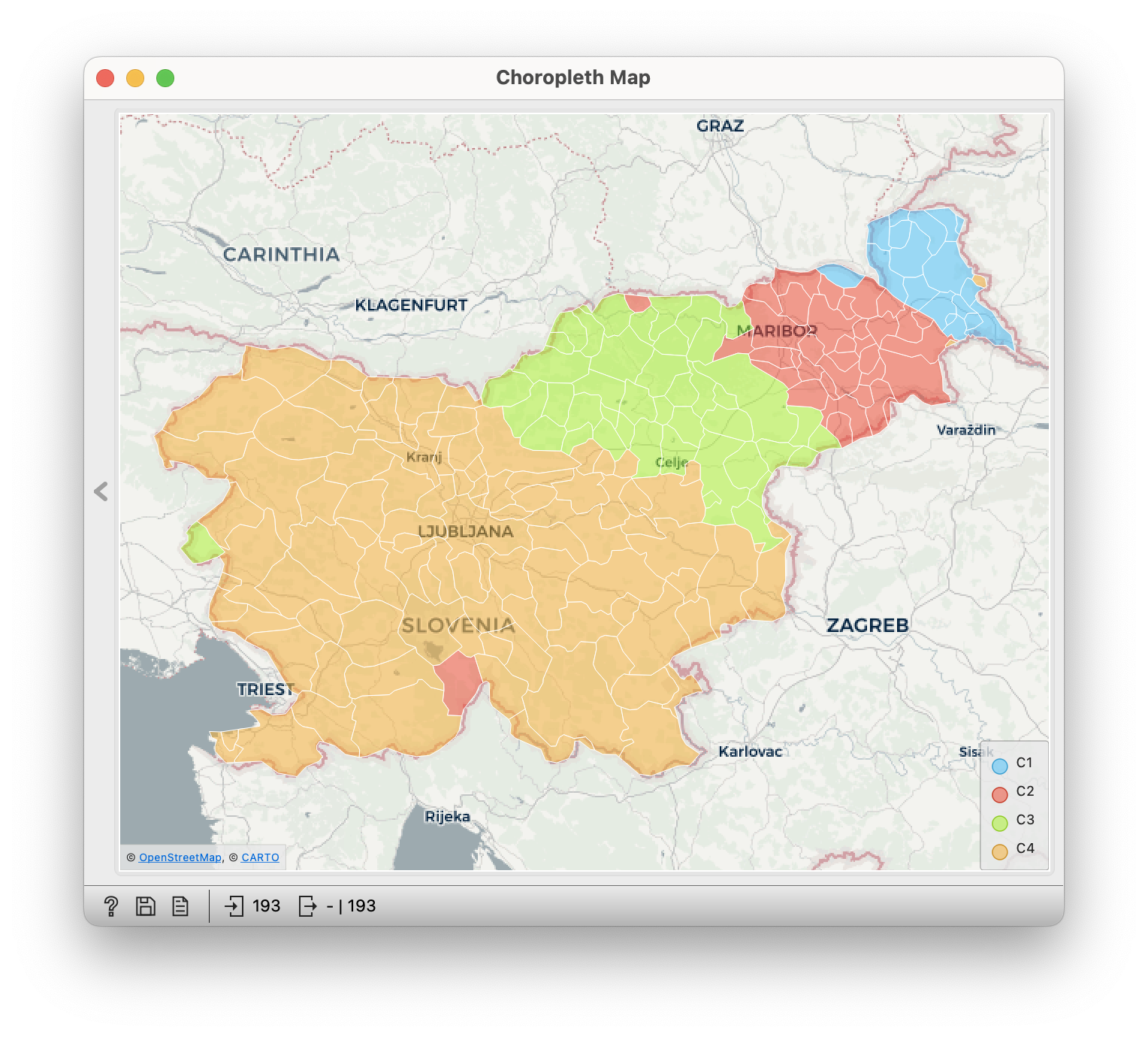 |
Only in five groups are Primorska (including northern Primorska, i.e. Bovec) and Notranjska separated from the main group. Anyone who has ever listened to how they speak in Ilirska Bistrica knows that they have more in common with the Primorska people than the Dolenjska or Rovtar people. Interestingly, this even extends to Ribnica. Perhaps this means that this part of Slovenia was more connected with Primorska and, further on, Trieste, than with the more northern or eastern parts of Slovenia. (What is the name of the region between Cerknica and Ribnica? Do we know of a famous Slovene who lived somewhere there and carried fire mushrooms and brussels and met the Emperor on one of his trading trips, who was on his way to Trieste in a carriage?)
In the six groups, the western Gorenjska and Rovtars (where are Rovte?) are on their way. Eastern Gorenjska (Kamnik), southern Štajerska ( more precisely: lower Posavje) and Dolenjska with Kočevska stay together.
So we can keep dividing as long as it makes sense.
Five clusters  | Six clusters  |
Similarities of surnames
If we load “municipalities-by-surnames.tab” instead of “surnames-by-municipalities.tab” in the File widget, we can do surname clustering. Those that are close in the clustering are more likely to be neighbours in reality. Unfortunately we can’t show them on the map, Distances calculates the differences between surnames, so the data from this point on only contains surnames, not their locations.
- Subject: slovenian, geography, history
- Duration: 1 hour
- Age: flexible
- AI topic: visualization, clustering
- Materials
- Preparation for the lesson
- the teacher can reflect on the students' surnames and their origins, typical surnames of the region, etc.
- computers with Orange and Geo add-on installed
Placement in the curriculum
This activity is not directly focused on a specific subject, but can be used to enrich a variety of subjects.