Monet versus Manet
Introduction
Edouard Manet and Claude Monet were French painters, contemporaries of the Modernist era. The work of both artists is extremely prolific, but it is easy for the layman to confuse one with the other. In this activity we will learn about the work of both painters and explore what distinguishes Monet from Manet.
To start, we upload 107 paintings by Edouard Manet (1832) and Claude Monet (1840). We ask students if they know either artist and why. What are their most famous works? Try to classify them into artistic movements. Manet is a member of Realism and later Impressionism, while Monet is a typical Impressionist throughout his career. Can a computer help us to identify the key differences between the two artists?
Observing the data
The data is uploaded to the Image Import widget and linked to the Image Viewer widget. This is where you can see which images you have uploaded. Let’s highlight some of the more famous ones, for example, Manet’s Luncheon on the grass and Monet’s Water lilies. If we only want to highlight two images, then we link the Image Import to the Table, select the two images in the Table and further link to the Image Viewer widget, where only the selected two images will be displayed.
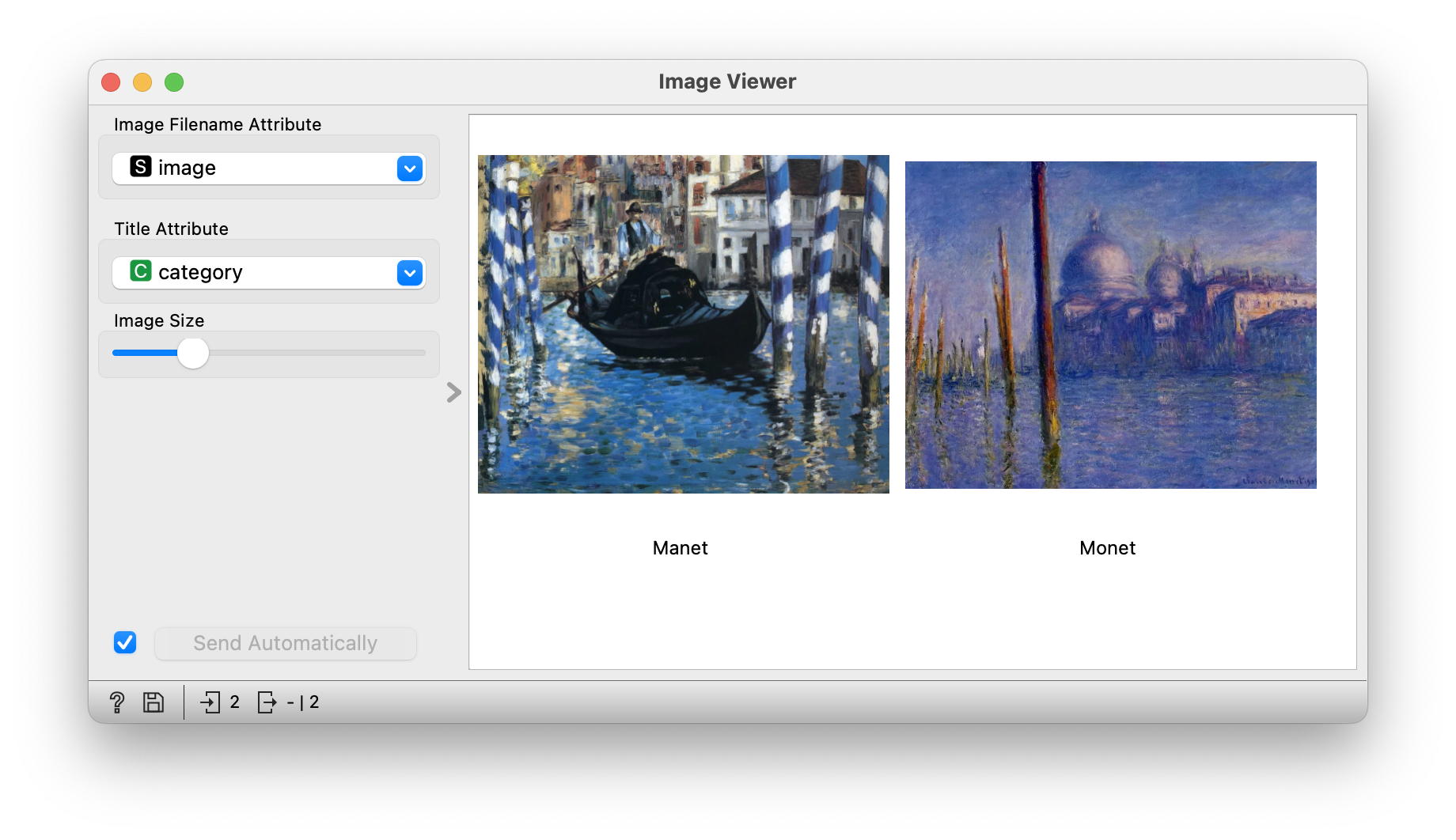
We also show pictures of The Grand Canal in Venice. Can they tell which of the paintings is Monet’s and which is Manet’s? We hint that this is already part of the evaluation algorithm called AUC, which is exactly that - if we have two paintings, one of which is Monet’s and one of which is Manet’s, how likely are we to get the artist right.
Deep neural networks and embeddings
A computer is an excellent mathematician, but not a very good art historian. It will not be able to work out anything clever from a picture alone. That is why we need to describe paintings with numbers.
How would the students describe the pictures? Artificial intelligence needs descriptions of the objects we are interested in to work. For example, images. We need to describe each image in a way that best represents its properties. Each individual property is called a feature. What would be the characteristics to distinguish between a Monet and a Manet?
Although counting the occurrence of a single colour could be quite effective, such a description captures nothing about the content of the image. Wouldn’t it be better to describe the image on the basis of its motif? For example, portraits would have different numerical descriptions than landscapes? For example, to count the appearances of eyes, noses, mouths, grass, trees and mountains? And compare the pictures on that basis?
Deep neural networks do something similar. These are complex algorithms that simulate human perception. We can imagine that a deep model recognises squares, diagonal lines, horizontal lines, triangles, ovals and so on in an image and uses this to construct a numerical description.
An example of such a model is Inception v3, which was learned by Google from 14 million images. The model successfully distinguishes between image motifs, e.g. recognising whether an image is of a duck or a car. In our example, it will determine which motif appears in the image.
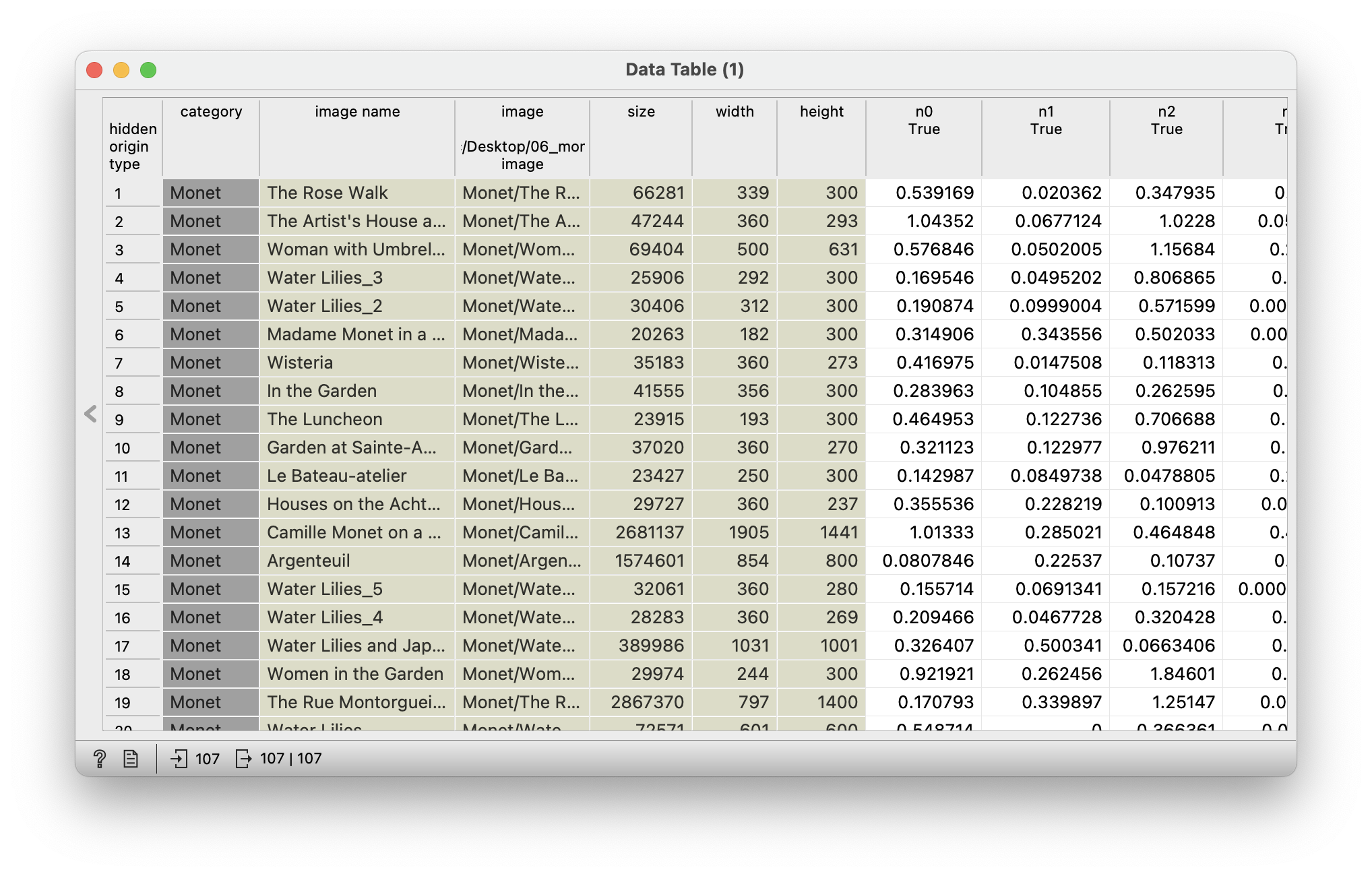
The problem is that we cannot explain these models. The features they return are completely incomprehensible to humans. We can check this by linking the Image Embedding widget (where Inception v3 is selected) to the Data Table and opening it.
Building a prediction model
When we describe the pictures with numbers, we can build a prediction model. First, we need an estimation procedure. This is defined in the Test and Score widget. We will use cross validation, which divides the data into equal groups and uses a different part of the data for learning and one for testing the model at each step. We evaluate the quality of the model using the AUC measure we remember from before. In a sense, this measure tells us how well we can identify the author from two images.
Then we need a learning process. We have chosen logistic regression, which we bring into the estimation procedure (Test and Score). The accuracy of the model is quite high, 0.925. The logistic regression is thus quite successful in distinguishing between the two painters.
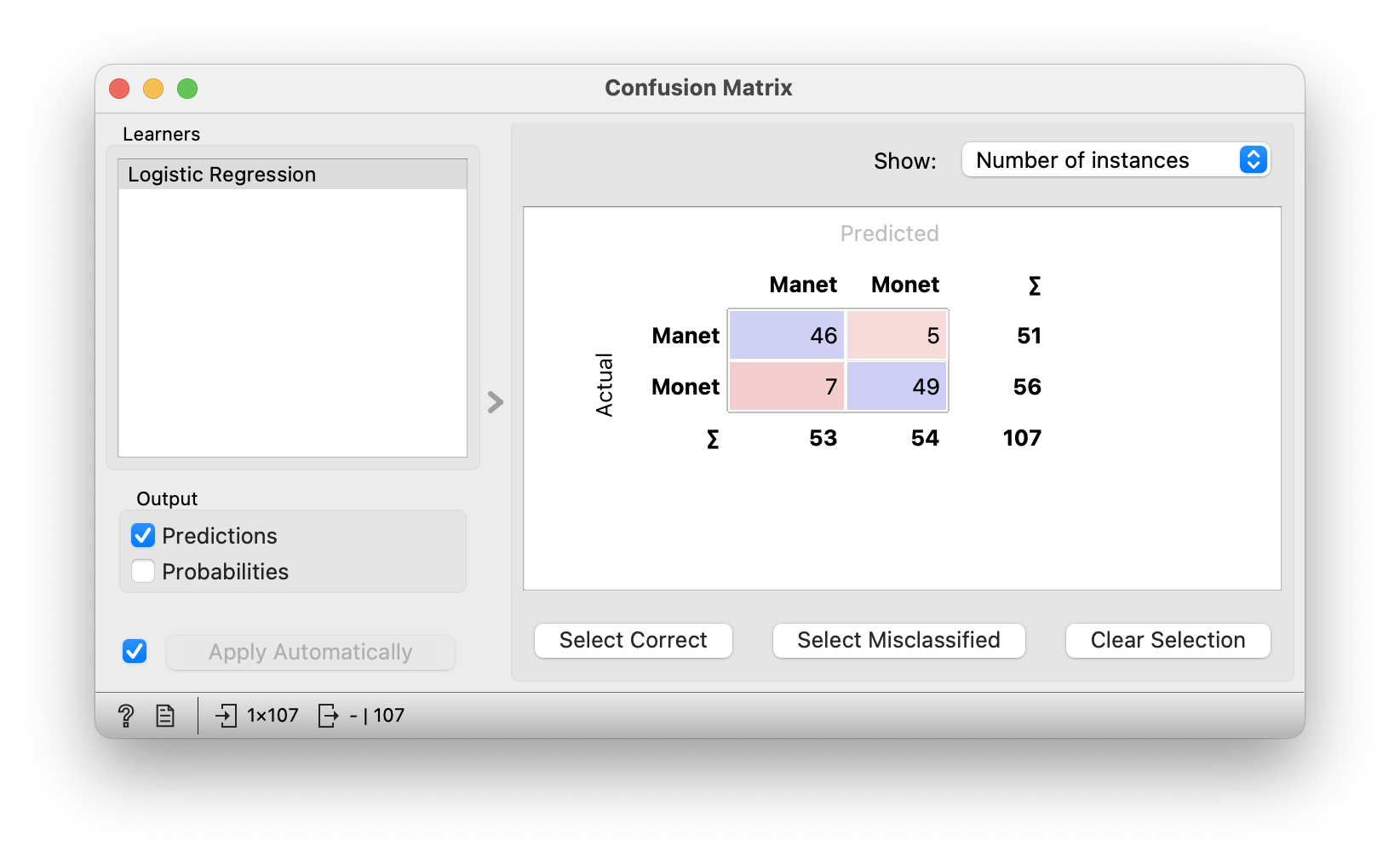
But it is still not infallible. Let’s see where the model went wrong. We do this with the Confusion Matrix widget. The diagonal, blue boxes contain the correctly predicted cases. In the red boxes, they are incorrectly predicted. For 5 examples, the model thinks they were painted by Monet, when in fact they were painted by Manet.
Let’s take a look at these paintings. Let’s select a field in the confusion matrix and look at the images in the Image Viewer widget. The misclassified Manet images contain greenery, water and soft strokes. These are typical characteristics of Monet’s style.
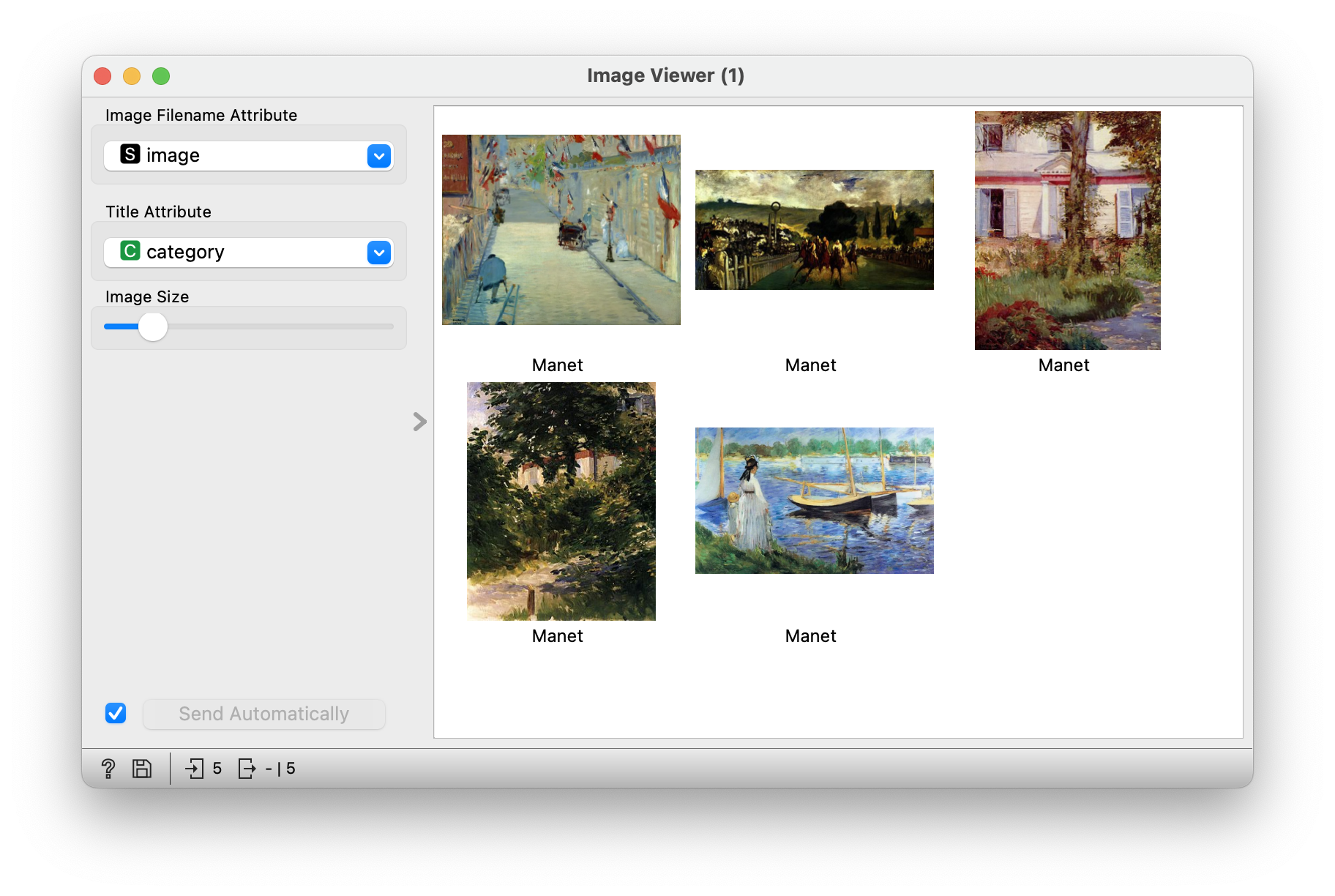
What about the other way around? Monet’s misclassified paintings contain human motifs and strong lines and contrasts. All that is characteristic of Manet’s style.
Conclusion
Prediction models and deep neural networks that embed images in numerical space are used everywhere today. One example is Google Search, where a user can search with the command “orange” and a background algorithm will be able to find images of oranges, even if they are not labelled with the term “orange”. Deep neural networks are also used in computer vision, for example in self-driving cars to detect types of objects on the road.
- Subject: art history
- Age: 2nd year
- AI topic: classification
- Materials
Placement in the curriculum
In terms of art history: students learn about the stylistic differences between Monet and Manet, two contemporaries of French Modernism. They investigate, independently or with the help of the teacher, which motifs are typical of which painter.
In terms of AI: students learn about the principles of neural networks and how they can be used to classify images. They learn that different models are suitable for different tasks, and they also learn how to build a simple classifier and investigate correctly and incorrectly classified examples.
Foreseen necessary widgets of Orange: Import Images, Image Embedding, Test and Score, Logistic Regression, Confusion Matrix, Image Viewer, Data Table
Activity is aligned with the teaching objectives of the subject:
- training to understand and analyse a work of art and to grasp the concepts of ideas in art,
- develops the ability to use words to describe works of art and phenomena in order to justify views, criteria and perspectives on fine art,
- teaches the correct use of different sources and the critical search and evaluation of information,
- develops the ability to learn and formulate concepts independently.